2013
Su, Yu; Agrawal, Gagan; Woodring, Jonathan; Myers, Kary; Wendelberger, Joanne; Ahrens, James
Taming massive distributed datasets: data sampling using bitmap indices Proceedings Article
In: Proceedings of the 22nd international symposium on High-performance parallel and distributed computing, pp. 13–24, ACM 2013, (LA-UR-pending).
Abstract | Links | BibTeX | Tags: bitmap indices, database applications, database management, performance
@inproceedings{su2013taming,
title = {Taming massive distributed datasets: data sampling using bitmap indices},
author = {Yu Su and Gagan Agrawal and Jonathan Woodring and Kary Myers and Joanne Wendelberger and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/TamingMassiveDistributedDatasetsDataSamplingUsingBitmapIndices.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Proceedings of the 22nd international symposium on High-performance parallel and distributed computing},
pages = {13--24},
organization = {ACM},
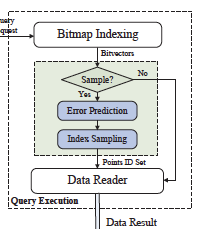
abstract = {In this paper, we address the data explosion problems by developing a novel sampling approach, and implementing it in a flexible system that supports server-side sampling and data subsetting. We observe that to allow subsetting over scientific datasets, data repositories are likely to use an indexing technique. Among these techniques, we see that bitmap indexing can not only effectively support subsetting over scientific datasets, but can also help create samples that preserve both value and spatial distributions over scientific datasets. We have developed algorithms for using bitmap indices to sample datasets. We have also shown how only a small amount of additional metadata stored with bitvectors can help assess loss of accuracy with a particular subsampling level. Some of the other properties of this novel approach include: 1) sampling can be flexibly applied to a subset of the original dataset, which may be specified using a value-based and/or a dimension-based subsetting predicate, and 2) no data reorganization is needed, once bitmap indices have been generated. We have extensively evaluated our method with different types of datasets and applications, and demonstrated the effectiveness of our approach.},
note = {LA-UR-pending},
keywords = {bitmap indices, database applications, database management, performance},
pubstate = {published},
tppubtype = {inproceedings}
}
Su, Yu; Agrawal, Gagan; Woodring, Jonathan; Myers, Kary; Wendelberger, Joanne; Ahrens, James
Taming massive distributed datasets: data sampling using bitmap indices Proceedings Article
In: Proceedings of the 22nd international symposium on High-performance parallel and distributed computing, pp. 13–24, ACM 2013, (LA-UR-pending).
@inproceedings{su2013taming,
title = {Taming massive distributed datasets: data sampling using bitmap indices},
author = {Yu Su and Gagan Agrawal and Jonathan Woodring and Kary Myers and Joanne Wendelberger and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/TamingMassiveDistributedDatasetsDataSamplingUsingBitmapIndices.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Proceedings of the 22nd international symposium on High-performance parallel and distributed computing},
pages = {13--24},
organization = {ACM},
abstract = {In this paper, we address the data explosion problems by developing a novel sampling approach, and implementing it in a flexible system that supports server-side sampling and data subsetting. We observe that to allow subsetting over scientific datasets, data repositories are likely to use an indexing technique. Among these techniques, we see that bitmap indexing can not only effectively support subsetting over scientific datasets, but can also help create samples that preserve both value and spatial distributions over scientific datasets. We have developed algorithms for using bitmap indices to sample datasets. We have also shown how only a small amount of additional metadata stored with bitvectors can help assess loss of accuracy with a particular subsampling level. Some of the other properties of this novel approach include: 1) sampling can be flexibly applied to a subset of the original dataset, which may be specified using a value-based and/or a dimension-based subsetting predicate, and 2) no data reorganization is needed, once bitmap indices have been generated. We have extensively evaluated our method with different types of datasets and applications, and demonstrated the effectiveness of our approach.},
note = {LA-UR-pending},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}