2011
Nouanesengsy, Boonthanome; Ahrens, James; Woodring, Jonathan; Shen, Han-Wei
Revisiting parallel rendering for shared memory machines Proceedings Article
In: Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization, pp. 31–40, Eurographics Association 2011, (LA-UR-11-02086).
Abstract | Links | BibTeX | Tags: hardware architecture, parallel processing, parallel rendering
@inproceedings{nouanesengsy2011revisiting,
title = {Revisiting parallel rendering for shared memory machines},
author = {Boonthanome Nouanesengsy and James Ahrens and Jonathan Woodring and Han-Wei Shen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/RevisitingParallelRenderingForSharedMemoryMachines.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization},
pages = {31--40},
organization = {Eurographics Association},
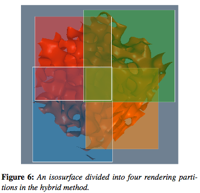
abstract = {Increasing the core count of CPUs to increase computational performance has been a significant trend for the better part of a decade. This has led to an unprecedented availability of large shared memory machines. Programming paradigms and systems are shifting to take advantage of this architectural change, so that intra-node parallelism can be fully utilized. Algorithms designed for parallel execution on distributed systems will also need to be modified to scale in these new shared and hybrid memory systems. In this paper, we reinvestigate parallel rendering algorithms with the goal of finding one that achieves favorable performance in this new environment. We test and analyze various methods, including sort-first, sort-last, and a hybrid scheme, to find an optimal parallel algorithm that maximizes shared memory performance.},
note = {LA-UR-11-02086},
keywords = {hardware architecture, parallel processing, parallel rendering},
pubstate = {published},
tppubtype = {inproceedings}
}
2003
Stompel, Aleksander; Ma, Kwan-Liu; Lum, Eric B; Ahrens, James; Patchett, John
SLIC: scheduled linear image compositing for parallel volume rendering Proceedings Article
In: Proceedings of the 2003 IEEE Symposium on Parallel and Large-Data Visualization and Graphics, pp. 6, IEEE Computer Society 2003, (LA-UR-03-5482).
Abstract | Links | BibTeX | Tags: high-performance computing, image com- positing, parallel rendering, PC clusters, visualization, vol- ume rendering
@inproceedings{stompel2003slic,
title = {SLIC: scheduled linear image compositing for parallel volume rendering},
author = {Aleksander Stompel and Kwan-Liu Ma and Eric B Lum and James Ahrens and John Patchett},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/SLICScheduledLinearImageCmpositingForParallelVolumeRendering.pdf},
year = {2003},
date = {2003-01-01},
booktitle = {Proceedings of the 2003 IEEE Symposium on Parallel and Large-Data Visualization and Graphics},
pages = {6},
organization = {IEEE Computer Society},
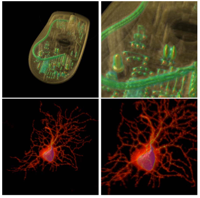
abstract = {Parallel volume rendering offers a feasible solution to the large data visualization problem by distributing both the data and rendering calculations among multiple computers connected by a network. In sort-last parallel volume rendering, each processor generates an image of its assigned subvolume, which is blended together with other images to derive the final image. Improving the efficiency of this compositing step, which requires interprocesssor communication, is the key to scalable, interactive rendering. The recent trend of using hardware-accelerated volume rendering demands further acceleration of the image compositing step. This paper presents a new optimized parallel image compositing algorithm and its performance on a PC cluster. Our test results show that this new algorithm offers significant savings over previous algorithms in both communication and compositing costs. On a 64-node PC cluster with a 100BaseT network interconnect, we can achieve interactive rendering rates for images at resolutions up to 1024 × 1024 pixels at several frames per second.},
note = {LA-UR-03-5482},
keywords = {high-performance computing, image com- positing, parallel rendering, PC clusters, visualization, vol- ume rendering},
pubstate = {published},
tppubtype = {inproceedings}
}
Nouanesengsy, Boonthanome; Ahrens, James; Woodring, Jonathan; Shen, Han-Wei
Revisiting parallel rendering for shared memory machines Proceedings Article
In: Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization, pp. 31–40, Eurographics Association 2011, (LA-UR-11-02086).
@inproceedings{nouanesengsy2011revisiting,
title = {Revisiting parallel rendering for shared memory machines},
author = {Boonthanome Nouanesengsy and James Ahrens and Jonathan Woodring and Han-Wei Shen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/RevisitingParallelRenderingForSharedMemoryMachines.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Proceedings of the 11th Eurographics conference on Parallel Graphics and Visualization},
pages = {31--40},
organization = {Eurographics Association},
abstract = {Increasing the core count of CPUs to increase computational performance has been a significant trend for the better part of a decade. This has led to an unprecedented availability of large shared memory machines. Programming paradigms and systems are shifting to take advantage of this architectural change, so that intra-node parallelism can be fully utilized. Algorithms designed for parallel execution on distributed systems will also need to be modified to scale in these new shared and hybrid memory systems. In this paper, we reinvestigate parallel rendering algorithms with the goal of finding one that achieves favorable performance in this new environment. We test and analyze various methods, including sort-first, sort-last, and a hybrid scheme, to find an optimal parallel algorithm that maximizes shared memory performance.},
note = {LA-UR-11-02086},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Stompel, Aleksander; Ma, Kwan-Liu; Lum, Eric B; Ahrens, James; Patchett, John
SLIC: scheduled linear image compositing for parallel volume rendering Proceedings Article
In: Proceedings of the 2003 IEEE Symposium on Parallel and Large-Data Visualization and Graphics, pp. 6, IEEE Computer Society 2003, (LA-UR-03-5482).
@inproceedings{stompel2003slic,
title = {SLIC: scheduled linear image compositing for parallel volume rendering},
author = {Aleksander Stompel and Kwan-Liu Ma and Eric B Lum and James Ahrens and John Patchett},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/SLICScheduledLinearImageCmpositingForParallelVolumeRendering.pdf},
year = {2003},
date = {2003-01-01},
booktitle = {Proceedings of the 2003 IEEE Symposium on Parallel and Large-Data Visualization and Graphics},
pages = {6},
organization = {IEEE Computer Society},
abstract = {Parallel volume rendering offers a feasible solution to the large data visualization problem by distributing both the data and rendering calculations among multiple computers connected by a network. In sort-last parallel volume rendering, each processor generates an image of its assigned subvolume, which is blended together with other images to derive the final image. Improving the efficiency of this compositing step, which requires interprocesssor communication, is the key to scalable, interactive rendering. The recent trend of using hardware-accelerated volume rendering demands further acceleration of the image compositing step. This paper presents a new optimized parallel image compositing algorithm and its performance on a PC cluster. Our test results show that this new algorithm offers significant savings over previous algorithms in both communication and compositing costs. On a 64-node PC cluster with a 100BaseT network interconnect, we can achieve interactive rendering rates for images at resolutions up to 1024 × 1024 pixels at several frames per second.},
note = {LA-UR-03-5482},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}