2011
Mitchell, Christopher; Ahrens, James; Wang, Jun
Visio: Enabling interactive visualization of ultra-scale, time series data via high-bandwidth distributed i/o systems Proceedings Article
In: Parallel & Distributed Processing Symposium (IPDPS), 2011 IEEE International, pp. 68–79, IEEE 2011, (LA-UR-10-07014).
Abstract | Links | BibTeX | Tags: distributed i/o, Parallel Computing, scientific visualization, ultra-scale, visualization
@inproceedings{mitchell2011visio,
title = {Visio: Enabling interactive visualization of ultra-scale, time series data via high-bandwidth distributed i/o systems},
author = {Christopher Mitchell and James Ahrens and Jun Wang},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/VisIO-IPDPS11.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Parallel & Distributed Processing Symposium (IPDPS), 2011 IEEE International},
pages = {68--79},
organization = {IEEE},
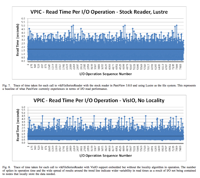
abstract = {Petascale simulations compute at resolutions ranging into billions of cells and write terabytes of data for visualization and analysis. Interactive visualization of this time series is a desired step before starting a new run. The I/O subsystem and associated network often are a significant impediment to interactive visualization of time-varying data; as they are not configured or provisioned to provide necessary I/O read rates. In this paper, we propose a new I/O library for visualization applications: VisIO. Visualization applications commonly use N- to-N reads within their parallel enabled readers which provides an incentive for a shared-nothing approach to I/O, similar to other data-intensive approaches such as Hadoop. However, unlike other data-intensive applications, visualization requires: (1) interactive performance for large data volumes, (2) compatibility with MPI and POSIX file system semantics for compatibility with existing infrastructure, and (3) use of existing file formats and their stipulated data partitioning rules. VisIO, provides a mechanism for using a non-POSIX distributed file system to provide linear scaling of I/O bandwidth. In addition, we introduce a novel scheduling algorithm that helps to co-locate visualization processes on nodes with the requested data. Testing using VisIO integrated into ParaView was conducted using the Hadoop Distributed File System (HDFS) on TACC’s Longhorn cluster. A representative dataset, VPIC, across 128 nodes showed a 64.4% read performance improvement compared to the provided Lustre installation. Also tested, was a dataset representing a global ocean salinity simulation that showed a 51.4% improvement in read performance over Lustre when using our VisIO system. VisIO, provides powerful high-performance I/O services to visualization applications, allowing for interactive performance with ultra-scale, time-series data.},
note = {LA-UR-10-07014},
keywords = {distributed i/o, Parallel Computing, scientific visualization, ultra-scale, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
Petascale simulations compute at resolutions ranging into billions of cells and write terabytes of data for visualization and analysis. Interactive visualization of this time series is a desired step before starting a new run. The I/O subsystem and associated network often are a significant impediment to interactive visualization of time-varying data; as they are not configured or provisioned to provide necessary I/O read rates. In this paper, we propose a new I/O library for visualization applications: VisIO. Visualization applications commonly use N- to-N reads within their parallel enabled readers which provides an incentive for a shared-nothing approach to I/O, similar to other data-intensive approaches such as Hadoop. However, unlike other data-intensive applications, visualization requires: (1) interactive performance for large data volumes, (2) compatibility with MPI and POSIX file system semantics for compatibility with existing infrastructure, and (3) use of existing file formats and their stipulated data partitioning rules. VisIO, provides a mechanism for using a non-POSIX distributed file system to provide linear scaling of I/O bandwidth. In addition, we introduce a novel scheduling algorithm that helps to co-locate visualization processes on nodes with the requested data. Testing using VisIO integrated into ParaView was conducted using the Hadoop Distributed File System (HDFS) on TACC’s Longhorn cluster. A representative dataset, VPIC, across 128 nodes showed a 64.4% read performance improvement compared to the provided Lustre installation. Also tested, was a dataset representing a global ocean salinity simulation that showed a 51.4% improvement in read performance over Lustre when using our VisIO system. VisIO, provides powerful high-performance I/O services to visualization applications, allowing for interactive performance with ultra-scale, time-series data.
: . .
1.
Mitchell, Christopher; Ahrens, James; Wang, Jun
Visio: Enabling interactive visualization of ultra-scale, time series data via high-bandwidth distributed i/o systems Proceedings Article
In: Parallel & Distributed Processing Symposium (IPDPS), 2011 IEEE International, pp. 68–79, IEEE 2011, (LA-UR-10-07014).
@inproceedings{mitchell2011visio,
title = {Visio: Enabling interactive visualization of ultra-scale, time series data via high-bandwidth distributed i/o systems},
author = {Christopher Mitchell and James Ahrens and Jun Wang},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/VisIO-IPDPS11.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Parallel & Distributed Processing Symposium (IPDPS), 2011 IEEE International},
pages = {68--79},
organization = {IEEE},
abstract = {Petascale simulations compute at resolutions ranging into billions of cells and write terabytes of data for visualization and analysis. Interactive visualization of this time series is a desired step before starting a new run. The I/O subsystem and associated network often are a significant impediment to interactive visualization of time-varying data; as they are not configured or provisioned to provide necessary I/O read rates. In this paper, we propose a new I/O library for visualization applications: VisIO. Visualization applications commonly use N- to-N reads within their parallel enabled readers which provides an incentive for a shared-nothing approach to I/O, similar to other data-intensive approaches such as Hadoop. However, unlike other data-intensive applications, visualization requires: (1) interactive performance for large data volumes, (2) compatibility with MPI and POSIX file system semantics for compatibility with existing infrastructure, and (3) use of existing file formats and their stipulated data partitioning rules. VisIO, provides a mechanism for using a non-POSIX distributed file system to provide linear scaling of I/O bandwidth. In addition, we introduce a novel scheduling algorithm that helps to co-locate visualization processes on nodes with the requested data. Testing using VisIO integrated into ParaView was conducted using the Hadoop Distributed File System (HDFS) on TACC’s Longhorn cluster. A representative dataset, VPIC, across 128 nodes showed a 64.4% read performance improvement compared to the provided Lustre installation. Also tested, was a dataset representing a global ocean salinity simulation that showed a 51.4% improvement in read performance over Lustre when using our VisIO system. VisIO, provides powerful high-performance I/O services to visualization applications, allowing for interactive performance with ultra-scale, time-series data.},
note = {LA-UR-10-07014},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Petascale simulations compute at resolutions ranging into billions of cells and write terabytes of data for visualization and analysis. Interactive visualization of this time series is a desired step before starting a new run. The I/O subsystem and associated network often are a significant impediment to interactive visualization of time-varying data; as they are not configured or provisioned to provide necessary I/O read rates. In this paper, we propose a new I/O library for visualization applications: VisIO. Visualization applications commonly use N- to-N reads within their parallel enabled readers which provides an incentive for a shared-nothing approach to I/O, similar to other data-intensive approaches such as Hadoop. However, unlike other data-intensive applications, visualization requires: (1) interactive performance for large data volumes, (2) compatibility with MPI and POSIX file system semantics for compatibility with existing infrastructure, and (3) use of existing file formats and their stipulated data partitioning rules. VisIO, provides a mechanism for using a non-POSIX distributed file system to provide linear scaling of I/O bandwidth. In addition, we introduce a novel scheduling algorithm that helps to co-locate visualization processes on nodes with the requested data. Testing using VisIO integrated into ParaView was conducted using the Hadoop Distributed File System (HDFS) on TACC’s Longhorn cluster. A representative dataset, VPIC, across 128 nodes showed a 64.4% read performance improvement compared to the provided Lustre installation. Also tested, was a dataset representing a global ocean salinity simulation that showed a 51.4% improvement in read performance over Lustre when using our VisIO system. VisIO, provides powerful high-performance I/O services to visualization applications, allowing for interactive performance with ultra-scale, time-series data.