2016

Patchett, John; Nouanesengsy, Boonthanome; Fasel, Patricia; Ahrens, James
2016 CSSE L3 Milestone: Deliver In Situ to XTD End Users Technical Report
2016, (LA-UR-16-26987).
Abstract | Links | BibTeX | Tags: in-situ, visualization
@techreport{Patchett2016,
title = {2016 CSSE L3 Milestone: Deliver In Situ to XTD End Users},
author = {John Patchett and Boonthanome Nouanesengsy and Patricia Fasel and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/10/DeliverInSituToXTDEndUsers.pdf},
year = {2016},
date = {2016-09-13},
abstract = {This report summarizes the activities in FY16 toward satisfying the CSSE 2016 L3 milestone to deliver in situ to XTD end users of EAP codes. The Milestone was accomplished with ongoing work to ensure the capability is maintained and developed. Two XTD end users used the in situ capability in Rage. A production ParaView capability was created in the HPC and Desktop environment. Two new capabilities were added to ParaView in support of an EAP in situ workflow.
We also worked with various support groups at the lab to deploy a production ParaView in the LANL environment for both desktop and HPC systems. . In addition, for this milestone, we moved two VTK based filters from research objects into the production ParaView code to support a variety of standard visualization pipelines for our EAP codes.},
note = {LA-UR-16-26987},
keywords = {in-situ, visualization},
pubstate = {published},
tppubtype = {techreport}
}
We also worked with various support groups at the lab to deploy a production ParaView in the LANL environment for both desktop and HPC systems. . In addition, for this milestone, we moved two VTK based filters from research objects into the production ParaView code to support a variety of standard visualization pipelines for our EAP codes.
2015
Adhinarayanan, Vignesh
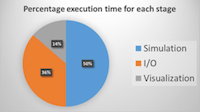
Performance, Power and Energy of In-situ and Post-processing Visualization: A Case Study in Climate Simulation Presentation
05.10.2015, (LA-UR-15-27749).
Abstract | Links | BibTeX | Tags: energy, in-situ, performance, post-processing, power
@misc{Adhinarayanan2015,
title = {Performance, Power and Energy of In-situ and Post-processing Visualization: A Case Study in Climate Simulation},
author = {Vignesh Adhinarayanan},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/07/PerformancePowerAndEnergyOfInSituAndPostProcessingVisualization.pdf},
year = {2015},
date = {2015-10-05},
abstract = {This presentation summarizes a summer study of the performance, power, and energy trade-offs among traditional post-processing, modern post-processing, and in-situ visualization pipelines. It includes both detailed sub-component level power measurements within a node to gain detailed insights and measurements at scale to understand problems unique to big supercomputers.},
note = {LA-UR-15-27749},
keywords = {energy, in-situ, performance, post-processing, power},
pubstate = {published},
tppubtype = {presentation}
}
Adhinarayanan, Vignesh; Feng, Wu-chun; Woodring, Jonathan; Rogers, David; Ahrens, James
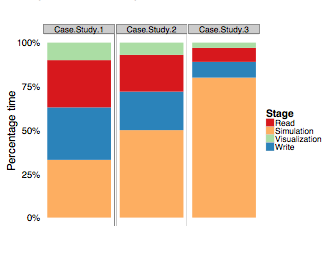
On the Greenness of In-Situ and Post-Processing Visualization Pipelines Proceedings Article
In: 11th workshop on High-Performance, Power-Aware Computing (HPPAC), Hyderabad, India, 2015, (LA-UR-15-21414).
Abstract | Links | BibTeX | Tags: greenness, in-situ, pipelines, post-processing, visualization
@inproceedings{vignesh-in-situ-hppac15,
title = {On the Greenness of In-Situ and Post-Processing Visualization Pipelines},
author = {Vignesh Adhinarayanan and Wu-chun Feng and Jonathan Woodring and David Rogers and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/OnTheGreenessOfIn-SituAndPost-ProcessingVisualizationPipelines.pdf},
year = {2015},
date = {2015-05-01},
booktitle = {11th workshop on High-Performance, Power-Aware Computing (HPPAC)},
address = {Hyderabad, India},
abstract = {Post-processing visualization pipelines are tradi- tionally used to gain insight from simulation data. However, changes to the system architecture for high-performance com- puting (HPC), dictated by the exascale goal, have limited the applicability of post-processing visualization. As an alternative, in-situ pipelines are proposed in order to enhance the knowl- edge discovery process via “real-time” visualization. Quantitative studies have already shown how in-situ visualization can improve performance and reduce storage needs at the cost of scientific exploration capabilities. However, to fully understand the trade- off space, a head-to-head comparison of power and energy (between the two types of visualization pipelines) is necessary. Thus, in this work, we study the greenness (i.e., power, energy, and energy efficiency) of the in-situ and the post-processing visualization pipelines, using a proxy heat-transfer simulation as an example. For a realistic I/O load, the in-situ pipeline consumes 43% less energy than the post-processing pipeline. Contrary to expectations, our findings also show that only 9% of the total energy is saved by reducing off-chip data movement, while the rest of the savings comes from reducing the system idle time. This suggests an alternative set of optimization techniques for reducing the power consumption of the traditional post- processing pipeline.},
note = {LA-UR-15-21414},
keywords = {greenness, in-situ, pipelines, post-processing, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
Sewell, Christopher; Heitmann, Katrin; Finkel, Hal; Zagaris, George; Parete-Koon, Suzanne; Fasel, Patricia; Pope, Adrian; Frontiere, Nicholas; Lo, Li-Ta; Messer, Bronson; Habib, Salman; Ahrens, James
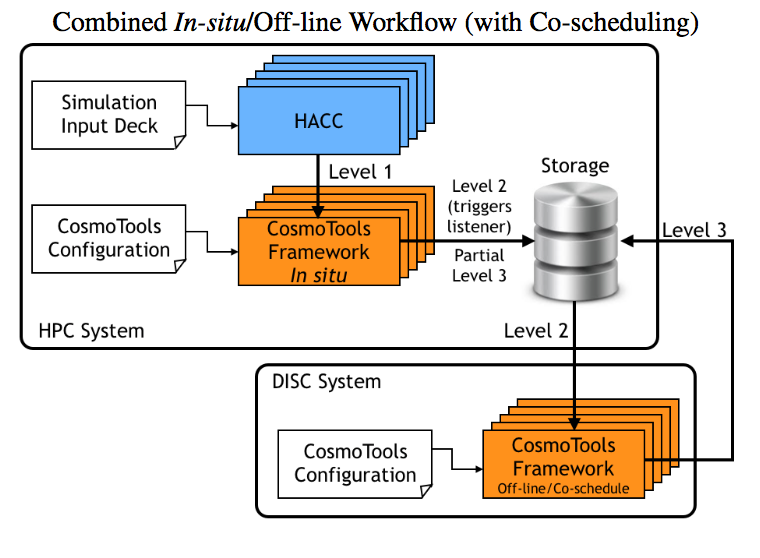
Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Press, Austin, Texas, 2015, (LA-UR-15-22830).
Abstract | Links | BibTeX | Tags: analysis, co-scheduling, compute-intensive, in-situ, large-scale, workflow
@inproceedings{Sewell:2015b,
title = {Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach},
author = {Christopher Sewell and Katrin Heitmann and Hal Finkel and George Zagaris and Suzanne Parete-Koon and Patricia Fasel and Adrian Pope and Nicholas Frontiere and Li-Ta Lo and Bronson Messer and Salman Habib and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/Large-ScaleCompute-IntensiveAnalysisViaACombinedIn-situAndCo-schedulingWorkflowApproach.pdf},
year = {2015},
date = {2015-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
publisher = {IEEE Press},
address = {Austin, Texas},
series = {SC '15},
abstract = {Large-scale simulations can produce hundreds of terabytes to peta- bytes of data, complicating and limiting the efficiency of work- flows. Traditionally, outputs are stored on the file system and an- alyzed in post-processing. With the rapidly increasing size and complexity of simulations, this approach faces an uncertain future. Trending techniques consist of performing the analysis in-situ, uti- lizing the same resources as the simulation, and/or off-loading sub- sets of the data to a compute-intensive analysis system. We intro- duce an analysis framework developed for HACC, a cosmological N-body code, that uses both in-situ and co-scheduling approaches for handling petabyte-scale outputs. We compare different anal- ysis set-ups ranging from purely off-line, to purely in-situ to in- situ/co-scheduling. The analysis routines are implemented using the PISTON/VTK-m framework, allowing a single implementation of an algorithm that simultaneously targets a variety of GPU, multi- core, and many-core architectures.},
note = {LA-UR-15-22830},
keywords = {analysis, co-scheduling, compute-intensive, in-situ, large-scale, workflow},
pubstate = {published},
tppubtype = {inproceedings}
}
2014

Ahrens, James; Jourdain, Sebastien; O'Leary, Patrick; Patchett, John; Rogers, David; Petersen, Mark
An Image-based Approach to Extreme Scale in Situ Visualization and Analysis Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 424–434, IEEE Press, New Orleans, Louisana, 2014, ISBN: 978-1-4799-5500-8, (LA-UR-14-26864).
Abstract | Links | BibTeX | Tags: analysis, cinema, cinemascience, image-based, in-situ, visualization
@inproceedings{Ahrens:2014:IAE:2683593.2683640,
title = {An Image-based Approach to Extreme Scale in Situ Visualization and Analysis},
author = {James Ahrens and Sebastien Jourdain and Patrick O'Leary and John Patchett and David Rogers and Mark Petersen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AnImage-basedApproachToExtremeScaleInSituvisualizationAndAnalysis.pdf
http://dx.doi.org/10.1109/SC.2014.40},
doi = {10.1109/SC.2014.40},
isbn = {978-1-4799-5500-8},
year = {2014},
date = {2014-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
pages = {424--434},
publisher = {IEEE Press},
address = {New Orleans, Louisana},
series = {SC '14},
abstract = {Extreme scale scientific simulations are leading a charge to exascale computation, and data analytics runs the risk of being a bottleneck to scientific discovery. Due to power and I/O constraints, we expect in situ visualization and analysis will be a critical component of these workflows. Options for extreme scale data analysis are often presented as a stark contrast: write large files to disk for interactive, exploratory analysis, or perform in situ analysis to save detailed data about phenomena that a scientists knows about in advance. We present a novel framework for a third option - a highly interactive, image-based approach that promotes exploration of simulation results, and is easily accessed through extensions to widely used open source tools. This in situ approach supports interactive exploration of a wide range of results, while still significantly reducing data movement and storage.},
note = {LA-UR-14-26864},
keywords = {analysis, cinema, cinemascience, image-based, in-situ, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
2013
Woodring, Jonathan; Ahrens, James; Tautges, Timothy J; Peterka, Tom; Vishwanath, Venkatram; Geveci, Berk
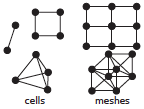
On-demand unstructured mesh translation for reducing memory pressure during in situ analysis Proceedings Article
In: Proceedings of the 8th International Workshop on Ultrascale Visualization, pp. 3, ACM 2013, (LA-UR-13-27909).
Abstract | Links | BibTeX | Tags: in-situ, memory pressure, mesh translation, on-demand, unstructured mesh
@inproceedings{woodring2013demand,
title = {On-demand unstructured mesh translation for reducing memory pressure during in situ analysis},
author = {Jonathan Woodring and James Ahrens and Timothy J Tautges and Tom Peterka and Venkatram Vishwanath and Berk Geveci},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/On-DemandUnstructuredMeshTranslationForReducingMemoryPressureDuringInSituAnalysis.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Proceedings of the 8th International Workshop on Ultrascale Visualization},
pages = {3},
organization = {ACM},
abstract = {When coupling two different mesh-based codes, for example with in situ analytics, the typical strategy is to explicitly copy data (deep copy) from one implementation to another, doing translation in the process. This is necessary because codes usually do not share data model interfaces or imple- mentations. The drawback is that data duplication results in an increased memory footprint for the coupled code. An alternative strategy, which we study in this paper, is to share mesh data through on-demand, fine-grained, run-time data model translation. This saves memory, which is an increas- ingly scarce resource at exascale, for the increased use of in situ analysis and decreasing memory per core. We study the performance of our method compared against a deep copy with in situ analysis at scale.},
note = {LA-UR-13-27909},
keywords = {in-situ, memory pressure, mesh translation, on-demand, unstructured mesh},
pubstate = {published},
tppubtype = {inproceedings}
}
2012
Sewell, Christopher; Meredith, Jeremy; Moreland, Kenneth; Peterka, Tom; DeMarle, David; Lo, Li-ta; Ahrens, James; Maynard, Robert; Geveci, Berk
The SDAV software frameworks for visualization and analysis on next-generation multi-core and many-core architectures Proceedings Article
In: High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:, pp. 206–214, IEEE 2012, (LA-UR-12-26928).
Abstract | Links | BibTeX | Tags: data-parallel, in-situ, many-core architectures, mult-core architectures, visualization, VTK-m
@inproceedings{sewell2012sdav,
title = {The SDAV software frameworks for visualization and analysis on next-generation multi-core and many-core architectures},
author = {Christopher Sewell and Jeremy Meredith and Kenneth Moreland and Tom Peterka and David DeMarle and Li-ta Lo and James Ahrens and Robert Maynard and Berk Geveci},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/TheSDAVSoftwareFrameworksForVisualizationAndAnalysisOnNext-GenerationMulti-CoreAndMany-CoreArchitectures.pdf},
year = {2012},
date = {2012-01-01},
booktitle = {High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:},
pages = {206--214},
organization = {IEEE},
abstract = {This paper surveys the four software frameworks being developed as part of the visualization pillar of the SDAV (Scalable Data Management, Analysis, and Visualization) Institute, one of the SciDAC (Scientific Discovery through Advanced Computing) Institutes established by the ASCR (Advanced Scientific Computing Research) Program of the U.S. Department of Energy. These frameworks include EAVL (Extreme-scale Analysis and Visualization Library), Dax (Data Analysis at Extreme), DIY (Do It Yourself), and PISTON. The objective of these frameworks is to facilitate the adaptation of visualization and analysis algorithms to take advantage of the available parallelism in emerging multi-core and manycore hardware architectures, in anticipation of the need for such algorithms to be run in-situ with LCF (leadership-class facilities) simulation codes on supercomputers.},
note = {LA-UR-12-26928},
keywords = {data-parallel, in-situ, many-core architectures, mult-core architectures, visualization, VTK-m},
pubstate = {published},
tppubtype = {inproceedings}
}
2011
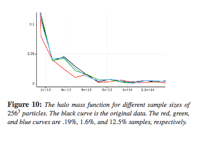
Woodring, Jonathan; Ahrens, James; Figg, Jeannette; Wendelberger, Joanne; Habib, Salman; Heitmann, Katrin
In-situ Sampling of a Large-Scale Particle Simulation for Interactive Visualization and Analysis Proceedings Article
In: Computer Graphics Forum, pp. 1151–1160, Wiley Online Library 2011, (LA-UR-11-02106).
Abstract | Links | BibTeX | Tags: in-situ, large-scale particle simulation, sampling, visualization
@inproceedings{woodring2011situ,
title = {In-situ Sampling of a Large-Scale Particle Simulation for Interactive Visualization and Analysis},
author = {Jonathan Woodring and James Ahrens and Jeannette Figg and Joanne Wendelberger and Salman Habib and Katrin Heitmann},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/In-situSamplingOfALarge-ScaleParticleSimulationForInteractiveVisualizationAndAnalysis.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Computer Graphics Forum},
volume = {30},
number = {3},
pages = {1151--1160},
organization = {Wiley Online Library},
abstract = {We describe a simulation-time random sampling of a large-scale particle simu lation, the RoadRunner Universe MC 3 cosmological simulation, for interactive post-analysis and visualization. Simu lation data generation rates will continue to be far greater than storage bandwidth rates by many orders of magnitude. This implies that only a very small fraction of data generated by a simulation can ever be stored a nd subsequently post-analyzed. The limiting factors in this situation are similar to the problem in many population surveys : there aren’t enough human resources to query a large population. To cope with the lack of resource s, statistical sampling techniques are used to create a representative data set of a large population. Following this analo gy, we propose to store a simulation-time random sampling of the particle data for post-analysis, with level-of-detail organization, to cope with the bottlenecks. A sample is stored directly from the simulation in a level-of-detail for mat for post-visualization and analysis, which amortizes the cost of post-processing and reduces wo rkflow time. Additionally by sampling during the simulation, we are able to analyze the entire particle population to record full population statistics and quantify sample error.},
note = {LA-UR-11-02106},
keywords = {in-situ, large-scale particle simulation, sampling, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
Patchett, John; Nouanesengsy, Boonthanome; Fasel, Patricia; Ahrens, James
2016 CSSE L3 Milestone: Deliver In Situ to XTD End Users Technical Report
2016, (LA-UR-16-26987).
@techreport{Patchett2016,
title = {2016 CSSE L3 Milestone: Deliver In Situ to XTD End Users},
author = {John Patchett and Boonthanome Nouanesengsy and Patricia Fasel and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/10/DeliverInSituToXTDEndUsers.pdf},
year = {2016},
date = {2016-09-13},
abstract = {This report summarizes the activities in FY16 toward satisfying the CSSE 2016 L3 milestone to deliver in situ to XTD end users of EAP codes. The Milestone was accomplished with ongoing work to ensure the capability is maintained and developed. Two XTD end users used the in situ capability in Rage. A production ParaView capability was created in the HPC and Desktop environment. Two new capabilities were added to ParaView in support of an EAP in situ workflow.
We also worked with various support groups at the lab to deploy a production ParaView in the LANL environment for both desktop and HPC systems. . In addition, for this milestone, we moved two VTK based filters from research objects into the production ParaView code to support a variety of standard visualization pipelines for our EAP codes.},
note = {LA-UR-16-26987},
keywords = {},
pubstate = {published},
tppubtype = {techreport}
}
We also worked with various support groups at the lab to deploy a production ParaView in the LANL environment for both desktop and HPC systems. . In addition, for this milestone, we moved two VTK based filters from research objects into the production ParaView code to support a variety of standard visualization pipelines for our EAP codes.
Adhinarayanan, Vignesh
Performance, Power and Energy of In-situ and Post-processing Visualization: A Case Study in Climate Simulation Presentation
05.10.2015, (LA-UR-15-27749).
@misc{Adhinarayanan2015,
title = {Performance, Power and Energy of In-situ and Post-processing Visualization: A Case Study in Climate Simulation},
author = {Vignesh Adhinarayanan},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/07/PerformancePowerAndEnergyOfInSituAndPostProcessingVisualization.pdf},
year = {2015},
date = {2015-10-05},
abstract = {This presentation summarizes a summer study of the performance, power, and energy trade-offs among traditional post-processing, modern post-processing, and in-situ visualization pipelines. It includes both detailed sub-component level power measurements within a node to gain detailed insights and measurements at scale to understand problems unique to big supercomputers.},
note = {LA-UR-15-27749},
keywords = {},
pubstate = {published},
tppubtype = {presentation}
}
Adhinarayanan, Vignesh; Feng, Wu-chun; Woodring, Jonathan; Rogers, David; Ahrens, James
On the Greenness of In-Situ and Post-Processing Visualization Pipelines Proceedings Article
In: 11th workshop on High-Performance, Power-Aware Computing (HPPAC), Hyderabad, India, 2015, (LA-UR-15-21414).
@inproceedings{vignesh-in-situ-hppac15,
title = {On the Greenness of In-Situ and Post-Processing Visualization Pipelines},
author = {Vignesh Adhinarayanan and Wu-chun Feng and Jonathan Woodring and David Rogers and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/OnTheGreenessOfIn-SituAndPost-ProcessingVisualizationPipelines.pdf},
year = {2015},
date = {2015-05-01},
booktitle = {11th workshop on High-Performance, Power-Aware Computing (HPPAC)},
address = {Hyderabad, India},
abstract = {Post-processing visualization pipelines are tradi- tionally used to gain insight from simulation data. However, changes to the system architecture for high-performance com- puting (HPC), dictated by the exascale goal, have limited the applicability of post-processing visualization. As an alternative, in-situ pipelines are proposed in order to enhance the knowl- edge discovery process via “real-time” visualization. Quantitative studies have already shown how in-situ visualization can improve performance and reduce storage needs at the cost of scientific exploration capabilities. However, to fully understand the trade- off space, a head-to-head comparison of power and energy (between the two types of visualization pipelines) is necessary. Thus, in this work, we study the greenness (i.e., power, energy, and energy efficiency) of the in-situ and the post-processing visualization pipelines, using a proxy heat-transfer simulation as an example. For a realistic I/O load, the in-situ pipeline consumes 43% less energy than the post-processing pipeline. Contrary to expectations, our findings also show that only 9% of the total energy is saved by reducing off-chip data movement, while the rest of the savings comes from reducing the system idle time. This suggests an alternative set of optimization techniques for reducing the power consumption of the traditional post- processing pipeline.},
note = {LA-UR-15-21414},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Sewell, Christopher; Heitmann, Katrin; Finkel, Hal; Zagaris, George; Parete-Koon, Suzanne; Fasel, Patricia; Pope, Adrian; Frontiere, Nicholas; Lo, Li-Ta; Messer, Bronson; Habib, Salman; Ahrens, James
Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Press, Austin, Texas, 2015, (LA-UR-15-22830).
@inproceedings{Sewell:2015b,
title = {Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach},
author = {Christopher Sewell and Katrin Heitmann and Hal Finkel and George Zagaris and Suzanne Parete-Koon and Patricia Fasel and Adrian Pope and Nicholas Frontiere and Li-Ta Lo and Bronson Messer and Salman Habib and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/Large-ScaleCompute-IntensiveAnalysisViaACombinedIn-situAndCo-schedulingWorkflowApproach.pdf},
year = {2015},
date = {2015-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
publisher = {IEEE Press},
address = {Austin, Texas},
series = {SC '15},
abstract = {Large-scale simulations can produce hundreds of terabytes to peta- bytes of data, complicating and limiting the efficiency of work- flows. Traditionally, outputs are stored on the file system and an- alyzed in post-processing. With the rapidly increasing size and complexity of simulations, this approach faces an uncertain future. Trending techniques consist of performing the analysis in-situ, uti- lizing the same resources as the simulation, and/or off-loading sub- sets of the data to a compute-intensive analysis system. We intro- duce an analysis framework developed for HACC, a cosmological N-body code, that uses both in-situ and co-scheduling approaches for handling petabyte-scale outputs. We compare different anal- ysis set-ups ranging from purely off-line, to purely in-situ to in- situ/co-scheduling. The analysis routines are implemented using the PISTON/VTK-m framework, allowing a single implementation of an algorithm that simultaneously targets a variety of GPU, multi- core, and many-core architectures.},
note = {LA-UR-15-22830},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Ahrens, James; Jourdain, Sebastien; O'Leary, Patrick; Patchett, John; Rogers, David; Petersen, Mark
An Image-based Approach to Extreme Scale in Situ Visualization and Analysis Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 424–434, IEEE Press, New Orleans, Louisana, 2014, ISBN: 978-1-4799-5500-8, (LA-UR-14-26864).
@inproceedings{Ahrens:2014:IAE:2683593.2683640,
title = {An Image-based Approach to Extreme Scale in Situ Visualization and Analysis},
author = {James Ahrens and Sebastien Jourdain and Patrick O'Leary and John Patchett and David Rogers and Mark Petersen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AnImage-basedApproachToExtremeScaleInSituvisualizationAndAnalysis.pdf
http://dx.doi.org/10.1109/SC.2014.40},
doi = {10.1109/SC.2014.40},
isbn = {978-1-4799-5500-8},
year = {2014},
date = {2014-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
pages = {424--434},
publisher = {IEEE Press},
address = {New Orleans, Louisana},
series = {SC '14},
abstract = {Extreme scale scientific simulations are leading a charge to exascale computation, and data analytics runs the risk of being a bottleneck to scientific discovery. Due to power and I/O constraints, we expect in situ visualization and analysis will be a critical component of these workflows. Options for extreme scale data analysis are often presented as a stark contrast: write large files to disk for interactive, exploratory analysis, or perform in situ analysis to save detailed data about phenomena that a scientists knows about in advance. We present a novel framework for a third option - a highly interactive, image-based approach that promotes exploration of simulation results, and is easily accessed through extensions to widely used open source tools. This in situ approach supports interactive exploration of a wide range of results, while still significantly reducing data movement and storage.},
note = {LA-UR-14-26864},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Woodring, Jonathan; Ahrens, James; Tautges, Timothy J; Peterka, Tom; Vishwanath, Venkatram; Geveci, Berk
On-demand unstructured mesh translation for reducing memory pressure during in situ analysis Proceedings Article
In: Proceedings of the 8th International Workshop on Ultrascale Visualization, pp. 3, ACM 2013, (LA-UR-13-27909).
@inproceedings{woodring2013demand,
title = {On-demand unstructured mesh translation for reducing memory pressure during in situ analysis},
author = {Jonathan Woodring and James Ahrens and Timothy J Tautges and Tom Peterka and Venkatram Vishwanath and Berk Geveci},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/On-DemandUnstructuredMeshTranslationForReducingMemoryPressureDuringInSituAnalysis.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Proceedings of the 8th International Workshop on Ultrascale Visualization},
pages = {3},
organization = {ACM},
abstract = {When coupling two different mesh-based codes, for example with in situ analytics, the typical strategy is to explicitly copy data (deep copy) from one implementation to another, doing translation in the process. This is necessary because codes usually do not share data model interfaces or imple- mentations. The drawback is that data duplication results in an increased memory footprint for the coupled code. An alternative strategy, which we study in this paper, is to share mesh data through on-demand, fine-grained, run-time data model translation. This saves memory, which is an increas- ingly scarce resource at exascale, for the increased use of in situ analysis and decreasing memory per core. We study the performance of our method compared against a deep copy with in situ analysis at scale.},
note = {LA-UR-13-27909},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Sewell, Christopher; Meredith, Jeremy; Moreland, Kenneth; Peterka, Tom; DeMarle, David; Lo, Li-ta; Ahrens, James; Maynard, Robert; Geveci, Berk
The SDAV software frameworks for visualization and analysis on next-generation multi-core and many-core architectures Proceedings Article
In: High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:, pp. 206–214, IEEE 2012, (LA-UR-12-26928).
@inproceedings{sewell2012sdav,
title = {The SDAV software frameworks for visualization and analysis on next-generation multi-core and many-core architectures},
author = {Christopher Sewell and Jeremy Meredith and Kenneth Moreland and Tom Peterka and David DeMarle and Li-ta Lo and James Ahrens and Robert Maynard and Berk Geveci},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/TheSDAVSoftwareFrameworksForVisualizationAndAnalysisOnNext-GenerationMulti-CoreAndMany-CoreArchitectures.pdf},
year = {2012},
date = {2012-01-01},
booktitle = {High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion:},
pages = {206--214},
organization = {IEEE},
abstract = {This paper surveys the four software frameworks being developed as part of the visualization pillar of the SDAV (Scalable Data Management, Analysis, and Visualization) Institute, one of the SciDAC (Scientific Discovery through Advanced Computing) Institutes established by the ASCR (Advanced Scientific Computing Research) Program of the U.S. Department of Energy. These frameworks include EAVL (Extreme-scale Analysis and Visualization Library), Dax (Data Analysis at Extreme), DIY (Do It Yourself), and PISTON. The objective of these frameworks is to facilitate the adaptation of visualization and analysis algorithms to take advantage of the available parallelism in emerging multi-core and manycore hardware architectures, in anticipation of the need for such algorithms to be run in-situ with LCF (leadership-class facilities) simulation codes on supercomputers.},
note = {LA-UR-12-26928},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Woodring, Jonathan; Ahrens, James; Figg, Jeannette; Wendelberger, Joanne; Habib, Salman; Heitmann, Katrin
In-situ Sampling of a Large-Scale Particle Simulation for Interactive Visualization and Analysis Proceedings Article
In: Computer Graphics Forum, pp. 1151–1160, Wiley Online Library 2011, (LA-UR-11-02106).
@inproceedings{woodring2011situ,
title = {In-situ Sampling of a Large-Scale Particle Simulation for Interactive Visualization and Analysis},
author = {Jonathan Woodring and James Ahrens and Jeannette Figg and Joanne Wendelberger and Salman Habib and Katrin Heitmann},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/In-situSamplingOfALarge-ScaleParticleSimulationForInteractiveVisualizationAndAnalysis.pdf},
year = {2011},
date = {2011-01-01},
booktitle = {Computer Graphics Forum},
volume = {30},
number = {3},
pages = {1151--1160},
organization = {Wiley Online Library},
abstract = {We describe a simulation-time random sampling of a large-scale particle simu lation, the RoadRunner Universe MC 3 cosmological simulation, for interactive post-analysis and visualization. Simu lation data generation rates will continue to be far greater than storage bandwidth rates by many orders of magnitude. This implies that only a very small fraction of data generated by a simulation can ever be stored a nd subsequently post-analyzed. The limiting factors in this situation are similar to the problem in many population surveys : there aren’t enough human resources to query a large population. To cope with the lack of resource s, statistical sampling techniques are used to create a representative data set of a large population. Following this analo gy, we propose to store a simulation-time random sampling of the particle data for post-analysis, with level-of-detail organization, to cope with the bottlenecks. A sample is stored directly from the simulation in a level-of-detail for mat for post-visualization and analysis, which amortizes the cost of post-processing and reduces wo rkflow time. Additionally by sampling during the simulation, we are able to analyze the entire particle population to record full population statistics and quantify sample error.},
note = {LA-UR-11-02106},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}