2016
Pulido, Jesus; Livescu, Daniel; Burns, Randal; Canada, Curt; Ahrens, James; Hamann, Bernd
Remote Visual Analysis on Large Turbulence Databases at Multiple Scales Presentation
Salishan Conference on High Speed Computing ; 2016-04-25 - 2016-04-29 ; Gleneden Beach, Oregon, United States, 21.04.2016, (LA-UR-16-22778).
Abstract | Links | BibTeX | Tags: large databases, visual analysis
@misc{info:lanl-repo/lareport/LA-UR-16-22778,
title = {Remote Visual Analysis on Large Turbulence Databases at Multiple Scales},
author = {Jesus Pulido and Daniel Livescu and Randal Burns and Curt Canada and James Ahrens and Bernd Hamann},
url = {http://datascience.dsscale.org/wp-content/uploads/2017/08/LA-UR-16-22778.pdf},
year = {2016},
date = {2016-04-21},
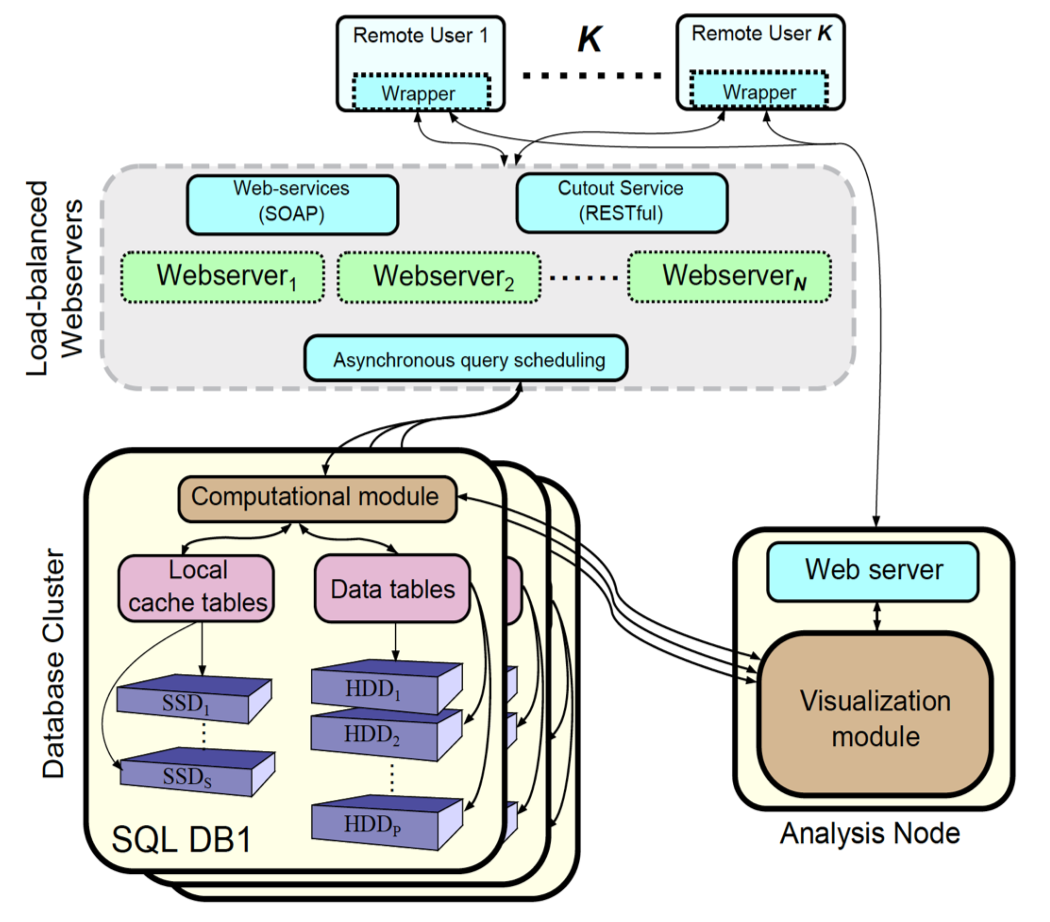
abstract = {Extremely large datasets are becoming increasingly common in science and engineering, and it is often prohibitive to store an original massive dataset at multiple sites or to transmit over computer networks in its entirety. Regardless, such datasets represented tremendous scientific value for the broader scientific community. It is imperative to deploy effective technologies enabling the remote access to vast data archives for the purpose of having a large pool of scientists harness their value and make new discoveries. Our analysis framework presented here was driven specifically by the needs articulated by scientists from Johns Hopkins University (JHU) and Los Alamos National Laboratory.},
howpublished = {Salishan Conference on High Speed Computing ; 2016-04-25 - 2016-04-29 ; Gleneden Beach, Oregon, United States},
note = {LA-UR-16-22778},
keywords = {large databases, visual analysis},
pubstate = {published},
tppubtype = {presentation}
}
Extremely large datasets are becoming increasingly common in science and engineering, and it is often prohibitive to store an original massive dataset at multiple sites or to transmit over computer networks in its entirety. Regardless, such datasets represented tremendous scientific value for the broader scientific community. It is imperative to deploy effective technologies enabling the remote access to vast data archives for the purpose of having a large pool of scientists harness their value and make new discoveries. Our analysis framework presented here was driven specifically by the needs articulated by scientists from Johns Hopkins University (JHU) and Los Alamos National Laboratory.
: . .
1.
Pulido, Jesus; Livescu, Daniel; Burns, Randal; Canada, Curt; Ahrens, James; Hamann, Bernd
Remote Visual Analysis on Large Turbulence Databases at Multiple Scales Presentation
Salishan Conference on High Speed Computing ; 2016-04-25 - 2016-04-29 ; Gleneden Beach, Oregon, United States, 21.04.2016, (LA-UR-16-22778).
@misc{info:lanl-repo/lareport/LA-UR-16-22778,
title = {Remote Visual Analysis on Large Turbulence Databases at Multiple Scales},
author = {Jesus Pulido and Daniel Livescu and Randal Burns and Curt Canada and James Ahrens and Bernd Hamann},
url = {http://datascience.dsscale.org/wp-content/uploads/2017/08/LA-UR-16-22778.pdf},
year = {2016},
date = {2016-04-21},
abstract = {Extremely large datasets are becoming increasingly common in science and engineering, and it is often prohibitive to store an original massive dataset at multiple sites or to transmit over computer networks in its entirety. Regardless, such datasets represented tremendous scientific value for the broader scientific community. It is imperative to deploy effective technologies enabling the remote access to vast data archives for the purpose of having a large pool of scientists harness their value and make new discoveries. Our analysis framework presented here was driven specifically by the needs articulated by scientists from Johns Hopkins University (JHU) and Los Alamos National Laboratory.},
howpublished = {Salishan Conference on High Speed Computing ; 2016-04-25 - 2016-04-29 ; Gleneden Beach, Oregon, United States},
note = {LA-UR-16-22778},
keywords = {},
pubstate = {published},
tppubtype = {presentation}
}
Extremely large datasets are becoming increasingly common in science and engineering, and it is often prohibitive to store an original massive dataset at multiple sites or to transmit over computer networks in its entirety. Regardless, such datasets represented tremendous scientific value for the broader scientific community. It is imperative to deploy effective technologies enabling the remote access to vast data archives for the purpose of having a large pool of scientists harness their value and make new discoveries. Our analysis framework presented here was driven specifically by the needs articulated by scientists from Johns Hopkins University (JHU) and Los Alamos National Laboratory.