2015
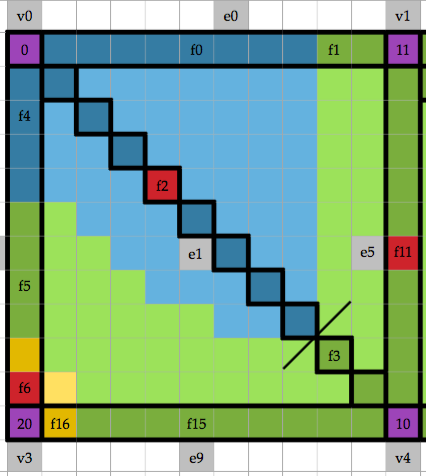
Carr, Hamish; Sewell, Christopher; Lo, Li-Ta; james Ahrens,
Hybrid Data-Parallel Contour Tree Computation Proceedings Article
In: 2015, (LA-UR-15-24759).
Abstract | Links | BibTeX | Tags: and object reppresentations, computational geometry and object modeling, contour tree, data-parallel, gpu, multi-core, nvidia thrust, simulation output analysis, solid, surface, topological analysis
@inproceedings{Carr2015,
title = {Hybrid Data-Parallel Contour Tree Computation},
author = {Hamish Carr and Christopher Sewell and Li-Ta Lo and james Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/HybridData-ParallelContourTreeComputaion.pdf},
year = {2015},
date = {2015-01-01},
number = {LA-UR-15-24759},
institution = {Los Alamos National Laboratory},
abstract = {As data sets increase in size beyond the petabyte, it is increasingly important to have automated methods for data analysis and visualization. While topological analysis tools such as the contour tree and Morse-Smale complex are now well established, there is still a shortage of efficient parallel algorithms for their computation, in particular for massively data-parallel computation on a SIMD model. We report the first data-parallel algorithm for computing the fully augmented contour tree, using a quantized computation model. We then extend this to provide a hybrid data-parallel / distributed algorithm allowing scaling beyond a single GPU or CPU, and provide results for its computation. Our implementation uses the portable data-parallel primitives provided by Nvidia’s Thrust library, allowing us to compile our same code for both GPUs and multi-core CPUs.},
note = {LA-UR-15-24759},
keywords = {and object reppresentations, computational geometry and object modeling, contour tree, data-parallel, gpu, multi-core, nvidia thrust, simulation output analysis, solid, surface, topological analysis},
pubstate = {published},
tppubtype = {inproceedings}
}

Heitmann, Katrin; Frontiere, Nicholas; Sewell, Christopher; Habib, Salman; Pope, Adrian; Finkel, Hal; Rizzi, Silvio; Insley, Joe; Bhattacharya, Suman
The Q Continuum Simulation: Harnessing the Power of GPU Accelerated Supercomputers Journal Article
In: 2015, (LA-UR-15-28271).
Abstract | Links | BibTeX | Tags: cosmology, gpu, n-body
@article{Heitmann:2015a,
title = {The Q Continuum Simulation: Harnessing the Power of GPU Accelerated Supercomputers},
author = {Katrin Heitmann and Nicholas Frontiere and Christopher Sewell and Salman Habib and Adrian Pope and Hal Finkel and Silvio Rizzi and Joe Insley and Suman Bhattacharya},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/11/TheQContinuumSimulationHarnessingThePowerOfGPUAcceleratedSupercomputers2.pdf},
year = {2015},
date = {2015-01-01},
publisher = {To appear in The Astrophysical Journal},
abstract = {Modeling large-scale sky survey observations is a key driver for the continuing development of high resolution, large-volume, cosmological simulations. We report the first results from the 'Q Continuum' cosmological N-body simulation run carried out on the GPU-accelerated supercomputer Titan. The simulation encompasses a volume of (1300 Mpc)^3 and evolves more than half a trillion particles, leading to a particle mass resolution of ~1.5 X 10^8 M_sun. At this mass resolution, the Q Continuum run is currently the largest cosmology simulation available. It enables the construction of detailed synthetic sky catalogs, encompassing different modeling methodologies, including semi-analytic modeling and sub-halo abundance matching in a large, cosmological volume. Here we describe the simulation and outputs in detail and present first results for a range of cosmological statistics, such as mass power spectra, halo mass functions, and halo mass-concentration relations for different epochs. We also provide details on challenges connected to running a simulation on almost 90% of Titan, one of the fastest supercomputers in the world, including our usage of Titan's GPU accelerators.},
note = {LA-UR-15-28271},
keywords = {cosmology, gpu, n-body},
pubstate = {published},
tppubtype = {article}
}
2014
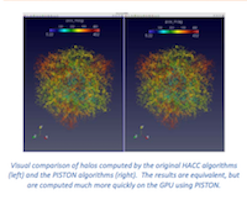
Sewell, Christopher; Ahrens, James; Patchett, John
New Data-parallel Algorithms Accelerate Cosmology Data Analysis on GPUs Presentation
30.06.2014, (LA-UR-14-22054).
Abstract | Links | BibTeX | Tags: cosmo, cosmology, data parallel, gpu
@misc{Sewell2014b,
title = {New Data-parallel Algorithms Accelerate Cosmology Data Analysis on GPUs},
author = {Christopher Sewell and James Ahrens and John Patchett},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/08/New_Data-parallel_Algorithms_Accelerate_Cosmology_Data_Analysis_on_GPUs.pdf},
year = {2014},
date = {2014-06-30},
abstract = {This presentation describes how new data-parallel algorithms have accelerated cosmology data analysis on GPUs.},
note = {LA-UR-14-22054},
keywords = {cosmo, cosmology, data parallel, gpu},
pubstate = {published},
tppubtype = {presentation}
}
2013

Sewell, Christopher
Portable Data-Parallel Visualization and Analysis Operators Presentation
20.03.2013, (LA-UR-13-21884).
Abstract | Links | BibTeX | Tags: data parallel, gpu, PINION, PISTON
@misc{Sewell2013,
title = {Portable Data-Parallel Visualization and Analysis Operators},
author = {Christopher Sewell},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/08/PortableDataParallelVisualizationAndAnalysisOperators.pdf},
year = {2013},
date = {2013-03-20},
abstract = {This presentation describes the overall goal of PISTON and PINION (to provide high parallel performance on current and next-generation supercomputers using portable, data-parallel code), and summarizes the work on these projects to date. It is intended for an audience at NVIDIA's GPU Technology Conference, and thus has an emphasis on how it uses Thrust to write code that obtains good parallel performance when compiled to different backends, including CUDA.},
note = {LA-UR-13-21884},
keywords = {data parallel, gpu, PINION, PISTON},
pubstate = {published},
tppubtype = {presentation}
}
Carr, Hamish; Sewell, Christopher; Lo, Li-Ta; james Ahrens,
Hybrid Data-Parallel Contour Tree Computation Proceedings Article
In: 2015, (LA-UR-15-24759).
@inproceedings{Carr2015,
title = {Hybrid Data-Parallel Contour Tree Computation},
author = {Hamish Carr and Christopher Sewell and Li-Ta Lo and james Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/HybridData-ParallelContourTreeComputaion.pdf},
year = {2015},
date = {2015-01-01},
number = {LA-UR-15-24759},
institution = {Los Alamos National Laboratory},
abstract = {As data sets increase in size beyond the petabyte, it is increasingly important to have automated methods for data analysis and visualization. While topological analysis tools such as the contour tree and Morse-Smale complex are now well established, there is still a shortage of efficient parallel algorithms for their computation, in particular for massively data-parallel computation on a SIMD model. We report the first data-parallel algorithm for computing the fully augmented contour tree, using a quantized computation model. We then extend this to provide a hybrid data-parallel / distributed algorithm allowing scaling beyond a single GPU or CPU, and provide results for its computation. Our implementation uses the portable data-parallel primitives provided by Nvidia’s Thrust library, allowing us to compile our same code for both GPUs and multi-core CPUs.},
note = {LA-UR-15-24759},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Heitmann, Katrin; Frontiere, Nicholas; Sewell, Christopher; Habib, Salman; Pope, Adrian; Finkel, Hal; Rizzi, Silvio; Insley, Joe; Bhattacharya, Suman
The Q Continuum Simulation: Harnessing the Power of GPU Accelerated Supercomputers Journal Article
In: 2015, (LA-UR-15-28271).
@article{Heitmann:2015a,
title = {The Q Continuum Simulation: Harnessing the Power of GPU Accelerated Supercomputers},
author = {Katrin Heitmann and Nicholas Frontiere and Christopher Sewell and Salman Habib and Adrian Pope and Hal Finkel and Silvio Rizzi and Joe Insley and Suman Bhattacharya},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/11/TheQContinuumSimulationHarnessingThePowerOfGPUAcceleratedSupercomputers2.pdf},
year = {2015},
date = {2015-01-01},
publisher = {To appear in The Astrophysical Journal},
abstract = {Modeling large-scale sky survey observations is a key driver for the continuing development of high resolution, large-volume, cosmological simulations. We report the first results from the 'Q Continuum' cosmological N-body simulation run carried out on the GPU-accelerated supercomputer Titan. The simulation encompasses a volume of (1300 Mpc)^3 and evolves more than half a trillion particles, leading to a particle mass resolution of ~1.5 X 10^8 M_sun. At this mass resolution, the Q Continuum run is currently the largest cosmology simulation available. It enables the construction of detailed synthetic sky catalogs, encompassing different modeling methodologies, including semi-analytic modeling and sub-halo abundance matching in a large, cosmological volume. Here we describe the simulation and outputs in detail and present first results for a range of cosmological statistics, such as mass power spectra, halo mass functions, and halo mass-concentration relations for different epochs. We also provide details on challenges connected to running a simulation on almost 90% of Titan, one of the fastest supercomputers in the world, including our usage of Titan's GPU accelerators.},
note = {LA-UR-15-28271},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Sewell, Christopher; Ahrens, James; Patchett, John
New Data-parallel Algorithms Accelerate Cosmology Data Analysis on GPUs Presentation
30.06.2014, (LA-UR-14-22054).
@misc{Sewell2014b,
title = {New Data-parallel Algorithms Accelerate Cosmology Data Analysis on GPUs},
author = {Christopher Sewell and James Ahrens and John Patchett},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/08/New_Data-parallel_Algorithms_Accelerate_Cosmology_Data_Analysis_on_GPUs.pdf},
year = {2014},
date = {2014-06-30},
abstract = {This presentation describes how new data-parallel algorithms have accelerated cosmology data analysis on GPUs.},
note = {LA-UR-14-22054},
keywords = {},
pubstate = {published},
tppubtype = {presentation}
}
Sewell, Christopher
Portable Data-Parallel Visualization and Analysis Operators Presentation
20.03.2013, (LA-UR-13-21884).
@misc{Sewell2013,
title = {Portable Data-Parallel Visualization and Analysis Operators},
author = {Christopher Sewell},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/08/PortableDataParallelVisualizationAndAnalysisOperators.pdf},
year = {2013},
date = {2013-03-20},
abstract = {This presentation describes the overall goal of PISTON and PINION (to provide high parallel performance on current and next-generation supercomputers using portable, data-parallel code), and summarizes the work on these projects to date. It is intended for an audience at NVIDIA's GPU Technology Conference, and thus has an emphasis on how it uses Thrust to write code that obtains good parallel performance when compiled to different backends, including CUDA.},
note = {LA-UR-13-21884},
keywords = {},
pubstate = {published},
tppubtype = {presentation}
}