2015
Sewell, Christopher; Heitmann, Katrin; Finkel, Hal; Zagaris, George; Parete-Koon, Suzanne; Fasel, Patricia; Pope, Adrian; Frontiere, Nicholas; Lo, Li-Ta; Messer, Bronson; Habib, Salman; Ahrens, James
Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Press, Austin, Texas, 2015, (LA-UR-15-22830).
Abstract | Links | BibTeX | Tags: analysis, co-scheduling, compute-intensive, in-situ, large-scale, workflow
@inproceedings{Sewell:2015b,
title = {Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach},
author = {Christopher Sewell and Katrin Heitmann and Hal Finkel and George Zagaris and Suzanne Parete-Koon and Patricia Fasel and Adrian Pope and Nicholas Frontiere and Li-Ta Lo and Bronson Messer and Salman Habib and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/Large-ScaleCompute-IntensiveAnalysisViaACombinedIn-situAndCo-schedulingWorkflowApproach.pdf},
year = {2015},
date = {2015-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
publisher = {IEEE Press},
address = {Austin, Texas},
series = {SC '15},
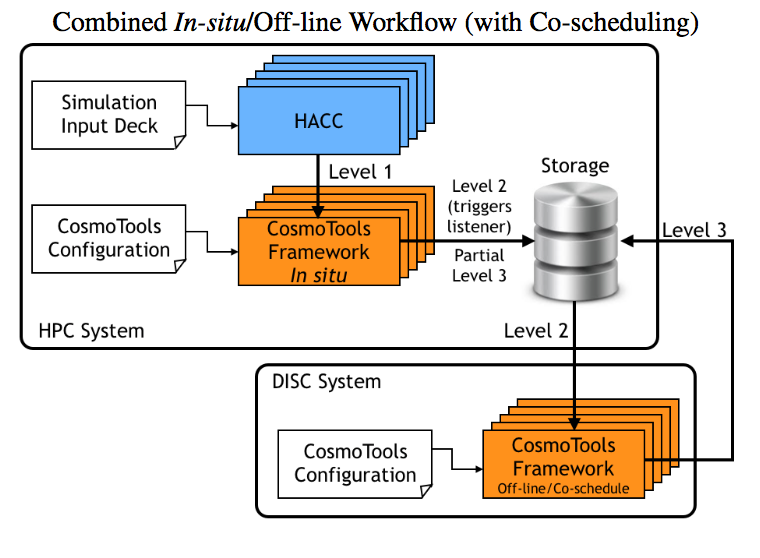
abstract = {Large-scale simulations can produce hundreds of terabytes to peta- bytes of data, complicating and limiting the efficiency of work- flows. Traditionally, outputs are stored on the file system and an- alyzed in post-processing. With the rapidly increasing size and complexity of simulations, this approach faces an uncertain future. Trending techniques consist of performing the analysis in-situ, uti- lizing the same resources as the simulation, and/or off-loading sub- sets of the data to a compute-intensive analysis system. We intro- duce an analysis framework developed for HACC, a cosmological N-body code, that uses both in-situ and co-scheduling approaches for handling petabyte-scale outputs. We compare different anal- ysis set-ups ranging from purely off-line, to purely in-situ to in- situ/co-scheduling. The analysis routines are implemented using the PISTON/VTK-m framework, allowing a single implementation of an algorithm that simultaneously targets a variety of GPU, multi- core, and many-core architectures.},
note = {LA-UR-15-22830},
keywords = {analysis, co-scheduling, compute-intensive, in-situ, large-scale, workflow},
pubstate = {published},
tppubtype = {inproceedings}
}
2008
Santos, Emanuele; Lins, Lauro; Ahrens, James; Freire, Juliana; Silva, Claudio T
A first study on clustering collections of workflow graphs Book Chapter
In: Provenance and Annotation of Data and Processes, pp. 160–173, Springer, 2008, (LA-UR-10-02553).
Abstract | Links | BibTeX | Tags: clustering, workflow
@inbook{Santos2008,
title = {A first study on clustering collections of workflow graphs},
author = {Emanuele Santos and Lauro Lins and James Ahrens and Juliana Freire and Claudio T Silva},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AFirstStudyOnClusteringCollectionsOfWorkflowGraphs.pdf},
year = {2008},
date = {2008-01-01},
booktitle = {Provenance and Annotation of Data and Processes},
pages = {160--173},
publisher = {Springer},
abstract = {As work ow systems get more widely used, the number of work ows and the volume of provenance they generate has grown considerably. New tools and infrastructure are needed to allow users to interact with, reason about, and re-use this information. In this paper, we explore the use of clustering techniques to organize large collections of work ow and provenance graphs. We propose two diㄦent representations for these graphs and present an experimental evaluation, using a collection of 1,700 work ow graphs, where we study the trade-oóof these representations and the ectiveness of alternative clustering techniques.},
note = {LA-UR-10-02553},
keywords = {clustering, workflow},
pubstate = {published},
tppubtype = {inbook}
}
Sewell, Christopher; Heitmann, Katrin; Finkel, Hal; Zagaris, George; Parete-Koon, Suzanne; Fasel, Patricia; Pope, Adrian; Frontiere, Nicholas; Lo, Li-Ta; Messer, Bronson; Habib, Salman; Ahrens, James
Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Press, Austin, Texas, 2015, (LA-UR-15-22830).
@inproceedings{Sewell:2015b,
title = {Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach},
author = {Christopher Sewell and Katrin Heitmann and Hal Finkel and George Zagaris and Suzanne Parete-Koon and Patricia Fasel and Adrian Pope and Nicholas Frontiere and Li-Ta Lo and Bronson Messer and Salman Habib and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/Large-ScaleCompute-IntensiveAnalysisViaACombinedIn-situAndCo-schedulingWorkflowApproach.pdf},
year = {2015},
date = {2015-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
publisher = {IEEE Press},
address = {Austin, Texas},
series = {SC '15},
abstract = {Large-scale simulations can produce hundreds of terabytes to peta- bytes of data, complicating and limiting the efficiency of work- flows. Traditionally, outputs are stored on the file system and an- alyzed in post-processing. With the rapidly increasing size and complexity of simulations, this approach faces an uncertain future. Trending techniques consist of performing the analysis in-situ, uti- lizing the same resources as the simulation, and/or off-loading sub- sets of the data to a compute-intensive analysis system. We intro- duce an analysis framework developed for HACC, a cosmological N-body code, that uses both in-situ and co-scheduling approaches for handling petabyte-scale outputs. We compare different anal- ysis set-ups ranging from purely off-line, to purely in-situ to in- situ/co-scheduling. The analysis routines are implemented using the PISTON/VTK-m framework, allowing a single implementation of an algorithm that simultaneously targets a variety of GPU, multi- core, and many-core architectures.},
note = {LA-UR-15-22830},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Santos, Emanuele; Lins, Lauro; Ahrens, James; Freire, Juliana; Silva, Claudio T
A first study on clustering collections of workflow graphs Book Chapter
In: Provenance and Annotation of Data and Processes, pp. 160–173, Springer, 2008, (LA-UR-10-02553).
@inbook{Santos2008,
title = {A first study on clustering collections of workflow graphs},
author = {Emanuele Santos and Lauro Lins and James Ahrens and Juliana Freire and Claudio T Silva},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AFirstStudyOnClusteringCollectionsOfWorkflowGraphs.pdf},
year = {2008},
date = {2008-01-01},
booktitle = {Provenance and Annotation of Data and Processes},
pages = {160--173},
publisher = {Springer},
abstract = {As work ow systems get more widely used, the number of work ows and the volume of provenance they generate has grown considerably. New tools and infrastructure are needed to allow users to interact with, reason about, and re-use this information. In this paper, we explore the use of clustering techniques to organize large collections of work ow and provenance graphs. We propose two diㄦent representations for these graphs and present an experimental evaluation, using a collection of 1,700 work ow graphs, where we study the trade-oóof these representations and the ectiveness of alternative clustering techniques.},
note = {LA-UR-10-02553},
keywords = {},
pubstate = {published},
tppubtype = {inbook}
}