Current Projects

ALPINE
ALPINE will deliver in situ analysis and visualization infrastructure, algorithms and lossy compression to exascale science applications as part of the Exascale Computing Project (ECP). ALPINE’s infrastructure includes common analysis tools such as ParaView and VisIt in addition to Ascent, a flyweight infrastructure library. It provides lossy compression through ZFP, a compressed multi-dimensional array primitive. A suite of in situ analysis algorithms supports feature and isosurface selection, sampling and data reduction, scalable statistics, flow analysis, and other domain-specific approaches for science insight development. The project maintains research efforts to develop and deploy its algorithms, infrastructure, and compression on exascale architectures and actively engages with Exascale science applications to integrate its software products into application codes.
ASC Production Visualization
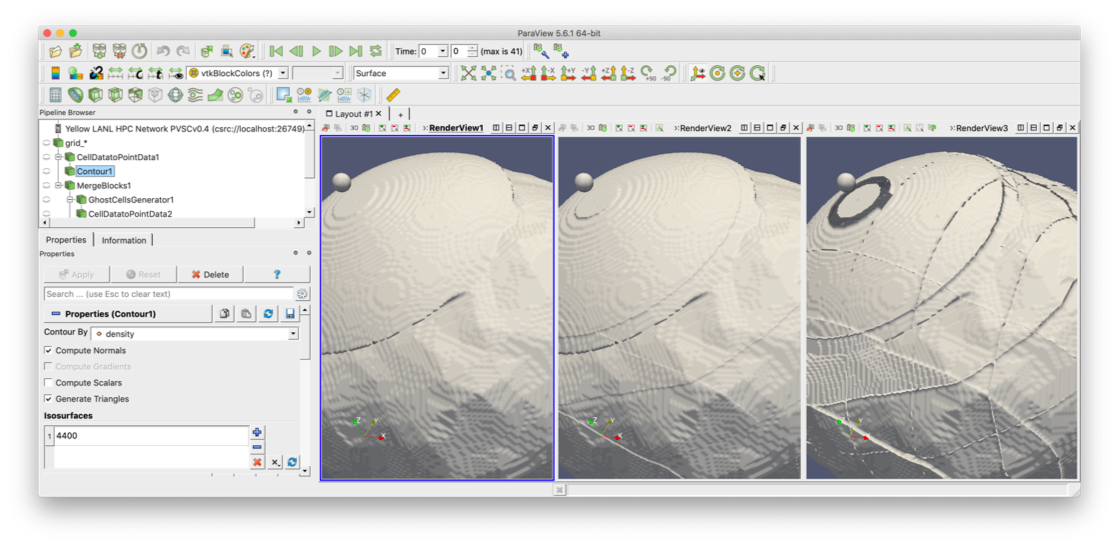
A key objective of the Visualization and Data Analysis project is to develop and support new visualization libraries and systems to meet capability requirements for ASC simulations. This work is required to address ASC workloads: massive data sizes, complex results, and the use of unique supercomputing architectures. For example, ASC simulations are currently producing massive amounts of data that threaten to outstrip the ability to visualize and analyze it. Therefore, it is important to understand the use of techniques such as in-situ analysis for data reduction and visualization kernels that run on the supercomputing platform, including data analysis, visualization, and rendering methods. We also provide LANL weapons designers with visualization systems support to fully utilize the systems provided. This project provides visualization services from the supercomputer to the desktop to expert support for users in the ASC program. Visualization and data analysis are essential tools needed by code teams and designers. Staff assists in the design and deployment of new machines, participating in design teams, troubleshooting graphics systems, and performing the visualization software integration tasks needed. The project has also deployed within the design community in X Division a small group of individuals with expert knowledge in both visualization and weapons science to work directly with the designers. This promotes new weapons science discoveries using the ASC codes.
ASC Vis R&D
A key objective of the Visualization and Data Analysis project is to develop new visualization libraries and systems to meet capability requirements for ASC simulations. This work is required to address ASC workloads: massive data sizes, complex results, and the use of unique supercomputing architectures. ASC simulations are currently producing massive amounts of data that threaten to outstrip the ability to visualize and analyze it. Therefore, it is important to understand how to triage data within the simulation as it is generated using techniques such as in-situ analysis for data reduction and visualization kernels that run on the supercomputing platform, including data analysis, visualization, and rendering methods. Cinema and workflow capabilities such as in-situ feature detection and post-processing algorithms, assist scientists in understanding data and making discoveries.
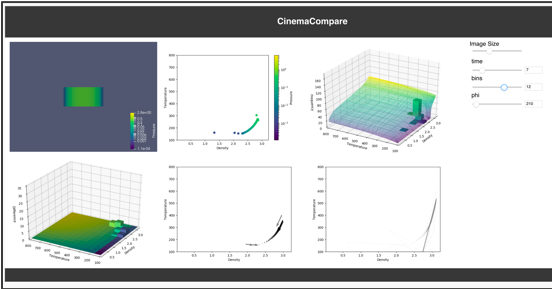
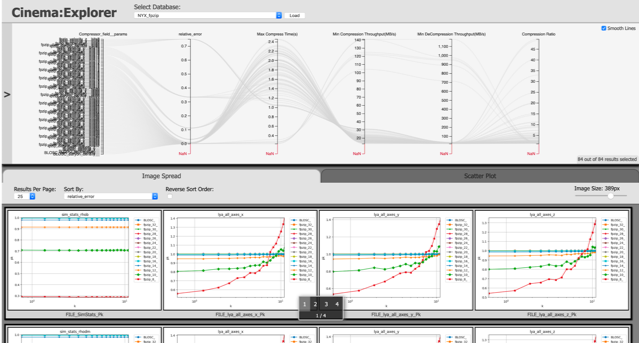
Cinema
The Cinema Project is focused on capabilities for analysis, exploration and visualization of extreme scale data for the Exascale Computing Project. The Cinema approach to data analysis is to capture important data in a Cinema database, analyze and visualize it with algorithms that operate on the artifacts captured, and view the data with any one of a number of lightweight viewers. The project maintains research efforts in in-situ data capture, analysis algorithms, and viewer design. In addition, Cinema promotes collaboration on data artifacts (what can be stored and retrieved from a Cinema database), and is working with third party partners such as Kitware and Intelligent Light to support in-situ and application workflows in common analysis tools such as ParaView and VisIt.

Exascale Computing Project
The fundamental exascale and ‘big data’ analysis challenge is that there is simply too much data and too little cognitive (human capacity for understanding) and computational bandwidth. In situ and online techniques that process and reduce data at the source are a promising approach forward. We propose to explore and evaluate two quantitative, sampling-based data-reduction approaches. The first is to intelligently down-scale the ‘raw’ data, producing reduced data representations for later visualization and analysis. The second is to intelligently sample the set of possible visualizations and analyses that can be generated, producing a database of selected data products for exploration. These intelligent data reduction approaches will significantly reduce the need for data movement, thus reducing associated supercomputer power costs, and increase scientific productivity by directing eyeballs to selected data.
ExaSky
The aim of the ExaSky project is to simulate all the processes in the structure and formation of the universe. There are two code bases/approaches, HACC, and NYX a particle and grid base trying to simulate. LANL’s contribution:
- Compression:
- Lossy Compression for HACC and NYX
- Compression Benchmark Framework
- HACC / NYX comparison
- Halo Finding Algorithms
- Octree based output and Visualization in ParaView
In-Situ Inference: Bringing Advanced Data Science Into Exascale Simulations
In this project, we focus on one class of grand challenge scientific problems: estimating the probability distribution of events of interest within an exascale simulation, along with the dependence of these distributions on space, time, and large-scale state within the simulation domain. Due to the unprecedented scale of data, now we need the ability to fit or train complex statistical models (statistical inference)as the simulations are running. We propose a number of fundamental advances in statistical inference and in-situ computer science. Scalable, distributed, streaming statistical models will be fit by fast approximate variational inference to spatiotemporal simulation data. We will create an in situ environment for data scientists to write powerful, concise, parallelized statistical algorithms with higher-level programming abstractions than Fortran/C++ and MPI.
NGC/FleCSI
Next Generation Code (NGC)/Flexible Computer Science Infrastructure (FeCSI) aims to resolve the tension between an aging Fortran development eco-system and the emerging exa-scale era for LANL’s scientific simulation community. It uses C++ programming language to provide computational scientist an intuitive way to express their numerical algorithms. It also leverages several contending exa-scale runtime systems like Legion, HPX and MPI.
Currently two hydrodynamics applications are built on top of FleCSI, a mesh based FleCSALE and a particle based FlecSPH.
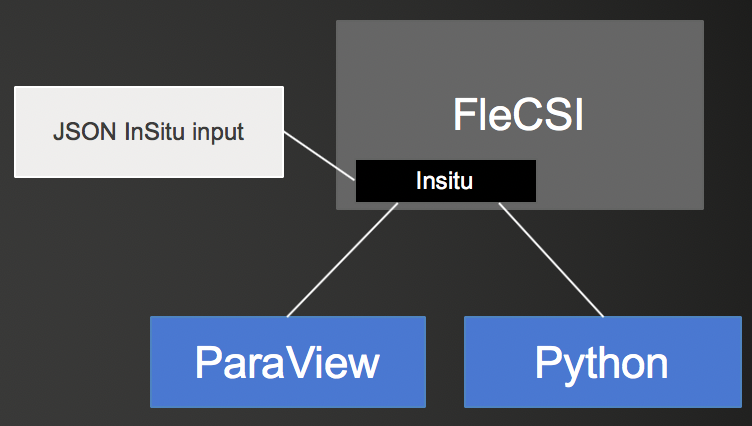
NGC-ATDM/In Situ for FleCSI
FleCSI is a compile-time configurable framework designed to support multi-physics application development. FLECSI has two backends, MPI and Legion.
The aim is to allow FleCSI users to query simulations as it is being run and possible change the parameters of the simulation while is it running. Aim:
- Support ParaView Visualization
- Provide triggers
- Python analysis
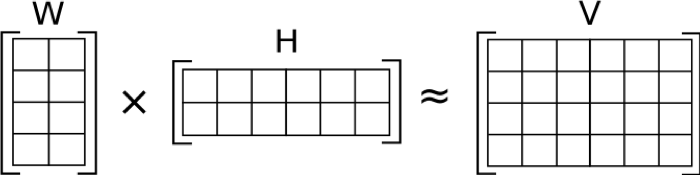
NNTF: Non-negative Tensor Factorization
- LANL’s Non-negative tensor factorization work promises to provide understandable elements of decomposition in Machine Learning
- Provide parallel performance analysis of LANL’s NMF algorithm
- Provide computer science consultation
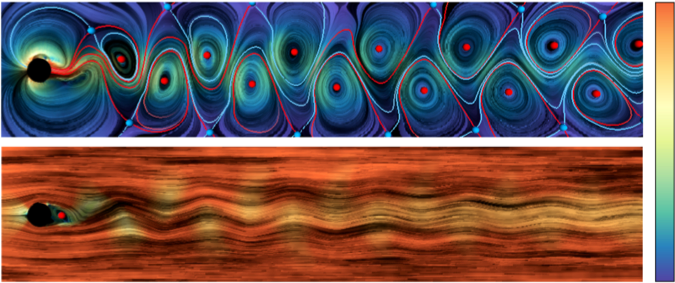
Objective Flow Topology
Flow topology is the most promising data reduction approach for flow data.
The topological skeleton of a vector field consists of its critical points (centers, sinks, sources, saddles) and separatrices. It separates the flow into regions in which all streamlines have the same origin and destination. The result is a highly compressed representation of the vector field that still contains all of the important features.
Sadly the classical vector field topology depends on the frame of reference.
We will develop a coherent mathematical framework that fills the gaps between the existing approaches toward objective (independent w.r.t. changes of the reference frame) flow topology.

Automatic Colormap Improvement in non-Euclidean Spaces
The utility of a visualization is highly linked to its colormap. A suboptimal colormap may hide information or introduce spurious artifacts. Empirical design guidelines (uniformity, discriminative power, order, and smoothness) are usually only applied ad hoc, and theory is not sufficiently developed to use a purely algorithmic approach.
RAPIDS
The objective of RAPIDS is to assist Office of Science (SC) application teams in overcoming computer science and data challenges in the use of DOE supercomputing resources to achieve science breakthroughs.
LANL works in the area of data understanding looking at performance visualization. We are mapping performance data to the simulations computational grid for visualization purposes.

VTKm
The VTKm project aims to provide a performance portable infrastructure for parallel visualization algorithms. This means that developers only need to write their code to the VTKm data-parallel application programming interface (API) once, then the library ensures their work will run on all kinds of acceleration hardware that currently exists and there will be, without any modification. The hard part is to learn advanced C++ programming techniques and to develop data-parallel visualization algorithms. Both are seldomly taught in school.
VTKm is the foundation of many data analysis and visualization projects of ECP. They use VTKm as delivery vehicle of their milestones.

4D Genome Browser
4DGB is an LDRD focused on creating, fusing, and exploring mulitimodal data for genomes. In particular, 3D estimated geometry is created, and epigenomics data is integrated, allowing novel querying and visual exploration of 3D data. There are several innovations that will result from the fusion of the data alone.
Past Projects
AESIST: Real-time Adaptive Acceleration of Dynamic Experimental Science
The AESIST is a research project aimed at achieving real-time analysis of experimental science, accelerating strategic components of the overall workflow, and providing timely feedback so scientists can adapt and optimize the experiment during beamtime. This capability will help scientists probe the linkages between materials microstructure and performance. This innovative data science capability will integrate experimental data with simulation results and uncertainty quantification to interactively guide the experimental process. Achieving this paradigm-changing, tightly coupled experiment, theory, and computation loop is critical to advancing materials science to match the national vision for predictive experimental control.

ASC Production
The ASC Production project supports a wide range of production activities for the LANL ASC program. It helps users understand their data with visualization and data analysis on exceptionally large data. It provides software on supercomputers, support and training for that software, and can produce analyses for users as well. It also identifies needed visualization and data analysis research and development tasks in order to facilitate needs of end users. ASC users can get routed to us through the normal LANL supercomputing support channels, or they can call us directly.

ASC Burst Buffer
The ASC Burst Buffer Next Generation Computing Technology project is aimed at high-risk, high-reward investigations that can enable ASC codes on new system architectures. The CSSE Burst Buffer investigation will look into alternative hierarchical storage technologies for support of in situ analysis, out-of-core processing, and data management. With the progressive march towards ever larger and faster HPC platforms, the discrepancy between the bandwidth available to the collective set of compute nodes and the bandwidth available on traditional parallel file systems utilizing hard disks has become mismatched. Rather than purchasing additional disks to increase bandwidth (beyond what is required for capacity requirements), the concept of a burst buffer has been proposed to impedance match the compute nodes to the storage system. A burst buffer is an allocation of fast, likely solid state, storage that is capable of absorbing a burst of I/O activity, which can then be slowly drained to a parallel file system while computation resumes within the running application. The original design intent of such a system was to handle the I/O workload commonly seen in the checkpoint-restart process which many current HPC applications use to handle faults. In ASC CSSE R&D, the CCS-7 data science at scale team has been exploring alternative uses for burst buffers to support Trinity, the first supercomputer to utilize burst buffer systems. We seek to use Trinity burst-buffers to improve scale-out performance of visualization and analysis tasks, which are typically I/O bound. This scale-out performance requires innovative design changes in the supercomputer architecture, such as burst buffers, and changes in the typical HPC analysis workflow, from traditional post-processing, to new in situ and in transit analytics. For example, the development of an ‘in-transit’ solution for data analytics, that utilize burst buffer technology, requires an understanding of the burst buffer’s capabilities. In support of this, a prototype burst buffer system has been constructed using estimates of expected technology and deployment strategy from the LANL Trinity project. Initial testing was completed on this prototype burst buffer in order to determine bandwidth capabilities (for both file read and write) under various I/O conditions, to determine how quickly data could be ingested and read back into memory for use, along with testing under analysis workload conditions. Future work will continue development on prototype Trinity hardware to develop new workflows to support exascale supercomputing.
ASC PINION
PINION is a portable, data-parallel software framework for physics simulations. PINION data structures allow scientists to program in a way that maps easily to the problem domain, while PINION operators provide data-parallel implementations of analysis and computational functions often used in physics simulations. Backend implementations of data parallel primitives are being optimized for emerging supercomputer hardware architectures such as Intel Xeon Phi (MIC).
ASCR Scalable Data Management, Analysis, and Visualization (SDAV) VTK-m
The goal of the SDAV VTK-m project within the Scalable Data Management, Analysis, and Visualization (SDAV) SciDAC Institute is to deliver multi-/many-core enabled visualization and analysis algorithms to scientific codes. VTK-m leverages the strengths of the Dax project at Sandia National Laboratory, the EAVL project at Oak Ridge National Laboratory, and the PISTON project at Los Alamos National Laboratory. The PISTON component of VTK-m focuses on developing data-parallel algorithms that are portable across multi-core and many-core architectures for use by LCF codes of interest, such as the HACC cosmology code. PISTON consists of a library of visualization and analysis algorithms implemented using NVIDIA’s Thrust library, as well as our set of extensions to Thrust. PISTON algorithms are integrated into LCF codes in-situ either directly or though ParaView Catalyst.
ASCR Co-Design Center for Exascale Simulation of Advanced Reactors (CESAR)
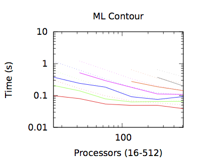
The Center for Exascale Simulation of Advanced Reactors (CESAR) is one of three Department of Energy-funded Co-Design Centers. The goal of CESAR is twofold: to both drive architectural decisions and adapt algorithms to the next generation HPC computer architectures on the path to exascale systems. CESAR’s particular focus is on the algorithms that underlie the high-fidelity analysis of nuclear reactors: namely, neutron transport (Boltzmann and Monte Carlo) and conjugate heat transfer (Navier Stokes). Thus, the CESAR co-design process involves continually evaluating complex architectural and algorithmic tradeoffs aimed ultimately at the design of both exascale computers and algorithms that can efficiently leverage them. LANL’s primary involvement is through the co-design of visualization and analysis codes at scale. When coupling two different mesh-based codes, for example with in situ analytics, the typical strategy is to explicitly copy data (deep copy) from one implementation to another, doing translation in the process. This is necessary because codes usually do not share data model interfaces or implementations. The drawback is that data duplication results in an increased memory footprint for the coupled code. An alternative strategy, which we study in this project, is to share mesh data through on-demand, fine-grained, run-time data model translation. This saves memory, which is an increasingly scarce resource at exascale, for the increased use of in situ analysis and decreasing memory per core. We study the performance of our method compared against a deep copy with in situ analysis at scale.

ASCR SciDac Plasma Surface Interactions (PSI)
Gaining physics understanding and predictive capabilities to describe the evolution of plasma facing components (PFC) requires simultaneously addressing complex and diverse physics occurring over a wide range of length and time scales, as well as integrating extensive physical processes across the plasma - surface - bulk materials boundaries. This requires development not only of detailed physics models and computational strategies at each of these scales, but computer science algorithms and methods to strongly couple them in a way that can be robustly validated through comparisons against available data and new experiments. Therefore, the objective of this project is to develop robust, high-fidelity simulation tools capable of predicting the PFC operating lifetime and the PFC impact on plasma contamination, recycling of hydrogenic species, and tritium retention in future magnetic fusion devices, with a focus on tungsten based material systems. Deploying these tools requires the development of a leadershipscale computational code, as well as a host of simulations that span the multiple scales needed to address complex physical and computational issues at the plasma - surface interface and the transition below the surface where neutron damage processes in the bulk material dominate behavior in multiple-component materials systems. Successful development will enable improved prediction of PFC performance needed to ensure magnetic fusion energy development beyond ITER.
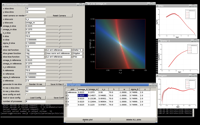
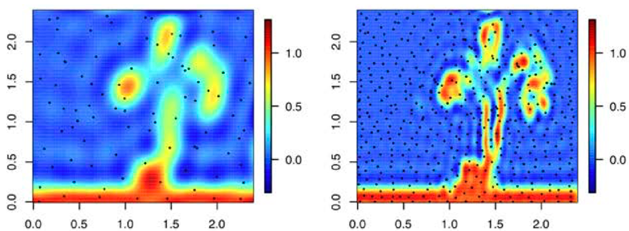
ASCR SciDAC Cosmology
Remarkable observational advances have established a compelling cross-validated model of the Universe. Yet, two key pillars of this model — dark matter and dark energy — remain mysterious. Next-generation sky surveys will map billions of galaxies to explore the physics of the ‘Dark Universe’. Science requirements for these surveys demand simulations at extreme scales; these will be delivered by the HACC (Hybrid/Hardware Accelerated Cosmology Code) framework. HACC’s novel algorithmic structure allows tuning across diverse architectures, including accelerated and multi-core systems, such as LANL’s Roadrunner in the past, and Argonne’s BG/Q in the present. HACC simulations at these scales will for the first time enable tracking individual galaxies over the entire volume of a cosmological survey. Analysing the results from future cosmological surveys, which promise measurements at the percent level accuracy, will be a daunting task. Theoretical predictions have to be at least as accurate, preferably even more accurate than the measurements themselves. For large scale structure probes, which explore the nonlinear regime of structure formation, this level of accuracy can only be achieved with costly high-performance simulations. Unlike in CMB analysis where one can generate a large number (tens to hundred thousand) of power spectra with fast codes like CAMB relatively easily this is impossible for large scale structure simulations. It is therefore important to develop fast prediction tools — emulators — based on a relatively small number of high-precision simulations which replace the simulator in the analysis work. To understand the emulator outputs is a daunting task itself, as they are multi-dimensional inputs which result in multi-dimensional outputs. The CCS-7 Data at Science Scale team is working on developing high-dimensional visualization tools to help with the exploration task of understanding the emulation process and science data. Images shown here are examples of a prototypical visualization system that connects directly to the emulator. Here, scientists are able to interactively use a wide variety of visualization techniques to understand the cosmological data, parameter study, and sensitivities of different cosmological parameters.
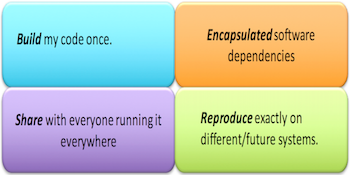
Build and Execution Environment
The goal of Build and Execution Environment (BEE) is to create a unified software stack to containerize HPC applications. BEE utilizes both virtual machines (VMs) and software containers to create a workflow system that establishes a uniform build and execution environment beyond the capabilities of current systems. In this environment, applications will run reliably and repeatably across heterogeneous hardware and software. Containers define the runtime that isolates all software dependency from the machine operating system. Workflows may contain multiple containers that run different operating systems, different software, and even different versions of the same software. Containers are placed in open-source virtual machine (KVM) and emulators (QEMU) so that workflows run on any machine entirely in user-space.

BER Accelerated Climate Modeling for Energy (ACME)
The Accelerated Climate Modeling for Energy (ACME) project is a newly launched project sponsored by the Earth System Modeling (ESM) program within U.S. Department of Energy’s (DOE’s) Office of Biological and Environmental Research. ACME is an unprecedented collaboration among eight national laboratories and six partner institutions to develop and apply the most complete, leading-edge climate and Earth system models to challenging and demanding climate-change research imperatives. It is the only major national modeling project designed to address DOE mission needs to efficiently utilize DOE leadership computing resources now and in the future.
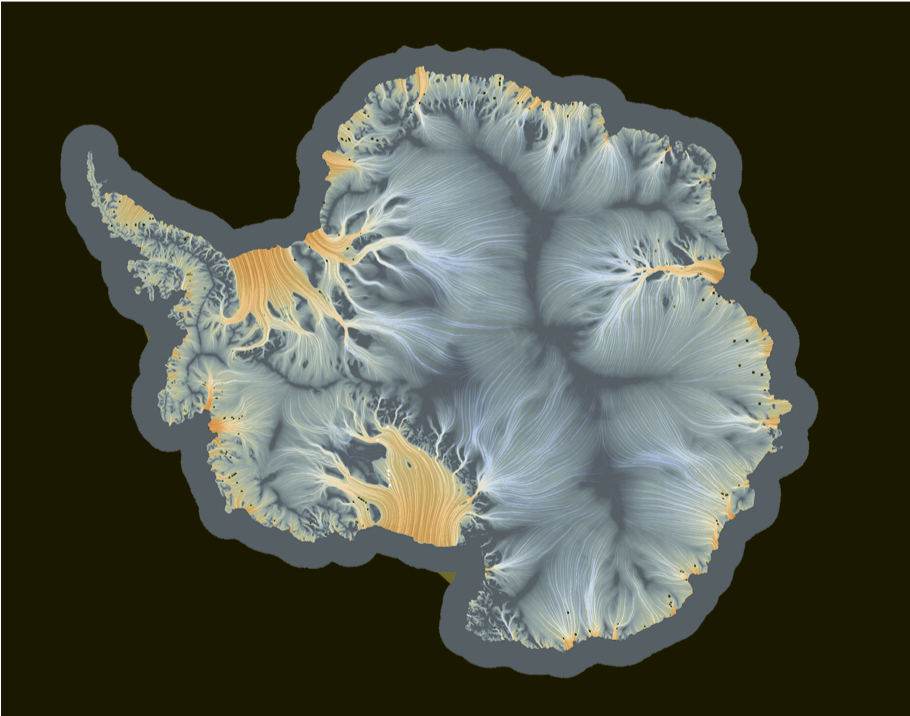
Cryosphere-Ocean
Scientific Visualization in support of the E3SM Cyrosphere Simulation Campaign
Develop a video submission to the 2020 SC Visualization and Data Analytics showcase using team sourcing to develop quality informative, reproducible visualizations.
- Visually show the interaction between ocean water and land ice.
- Improve ParaView’s ability to store and restore visualization definitions.
- Support visual communication to domain scientists, program managers, and the general public.

LDRD Mesoscale Materials Science of Ductile Damage in Four Dimensions
The recent development of novel synchrotron x-ray diffraction techniques is now enabling in-situ 3-D characterization of polycrystalline materials, providing tomography, crystal orientation fields and local stress mapping. Here we report our initial efforts to draw upon these techniques, integrating and combining them with appropriate modeling and data analysis formulations, to discover relationships between microstructure and ductile damage in polycrystalline aggregates. Our ultimate goal is to develop a predictive tool for materials discovery that can master defect meso-structure and its evolution to control structural properties.
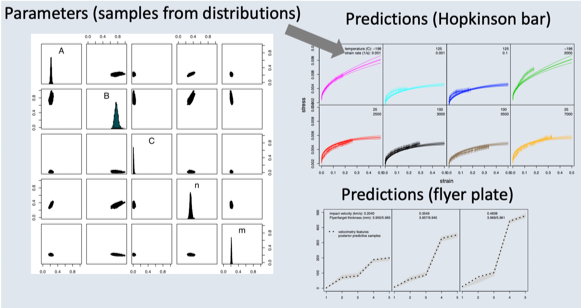
Parameter Tuning and Physics Model Comparison Using Statistical Learning
- Materials scientists use a variety of flow stress models to evaluate material properties, ranging from purely empirical (e.g. Johnson-Cook), to being more physically motivated (Preston-Tonks-Wallace model).
- We demonstrate tools to validate and compare models using statistical learning methods. We incorporate data from multiple simulations and experiments for parameter tuning and model comparison.
- We incorporate Bayesian inferential methods, allowing for full quantification of uncertainty for Aluminum and Copper alloys.
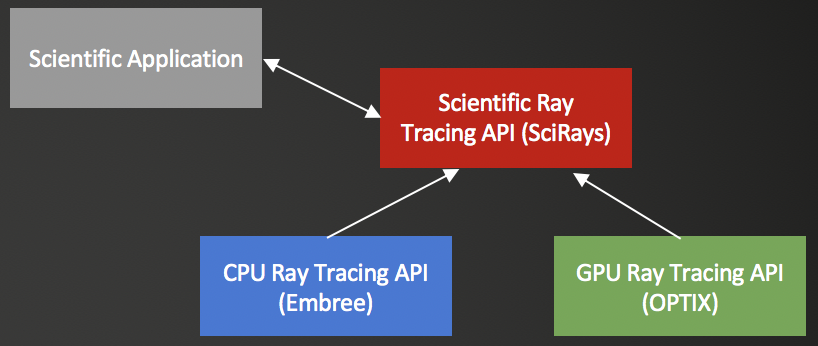
Scientific RayTracing
Most ray tracing packages focus on rendering images. However, ray tracing is also used in scientific applications ranging from neutron transport to cloud ionization. The aim of this project is to Create an API and demonstrate that it can be used for scientific applications. The benefits:
- Use decades of experience from the graphics community to speed up ray tracing
- Speed up code development by leveraging existing code
- Modernize scientific ray tracing apps.
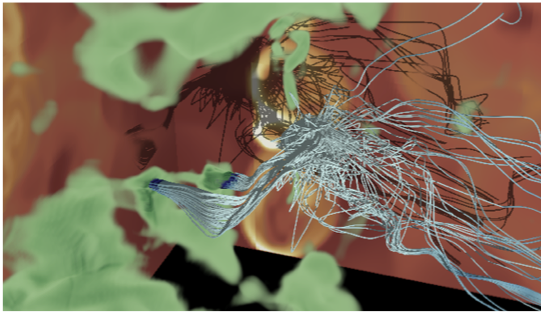
Stardust
The Stardust project is a perceptually and cognitively driven approach to data analysis using an asynchronous tasking engine. Scientific data from simulation and experiments are increasing in size by orders of magnitude each year. This is due to the advancing quality of scientific simulations driven by the Department of Energy’s multi-decadal simulation software, system software and hardware acceleration programs. This project addresses massive data by leveraging ray-based operations in optimized commercial libraries, and implementing an asynchronous engine that can be used as either a rendering or sampling engine. The result is faster processing of massive data, without the creation of intermediate geometry, which operating on a subset of the data intersected by rays, rather than the entire dataset.

Topological Data Analysis for VPIC
This project handles the relations between topological analysis and the physical implications of those analyses to 2D vector particle-in-cell (VPIC) simulations.
We explore the applications of level sets, topological segmentation, critical points and Morse-Smale complex to VPIC data.
Our eventual goals are to track segmented features over time and to apply similar techniques to 3D VPIC simulations.