1994
Shapiro, Linda; Tanimoto, Steven; Brinkley, James; Ahrens, James; Jakobovits, Rex; Lewis, Lara
A visual database system for data and experiment management in model-based computer vision Proceedings Article
In: CAD-Based Vision Workshop, 1994., Proceedings of the 1994 Second, pp. 64–72, IEEE 1994, (LA-UR-pending).
Abstract | Links | BibTeX | Tags: model-based computer vision, visual database
@inproceedings{shapiro1994visual,
title = {A visual database system for data and experiment management in model-based computer vision},
author = {Linda Shapiro and Steven Tanimoto and James Brinkley and James Ahrens and Rex Jakobovits and Lara Lewis},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AVisualDatabaseSystemForDataAndExperimentManagementInModel-BasedComputerVision.pdf},
year = {1994},
date = {1994-01-01},
booktitle = {CAD-Based Vision Workshop, 1994., Proceedings of the 1994 Second},
pages = {64--72},
organization = {IEEE},
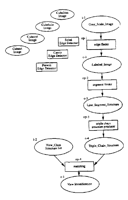
abstract = {Computer vision researchers work with many different forms of data. Model-based vision systems work with geometric models of 3D objects, intensity or range images, and many different kinds of features that are extracted from these images. The recognition/pose estimation process involves a number of different steps and different operations all of which take in and generate various forms of data. Figure 1 illustrates the operations and data types required for a sample recognition process (Shapiro, Neal, and Ponder; 1992). The process starts with a gray-scale image and produces an edge image, a line segment structure, and a triple chain structure (described in Section 2). Each object in the model database is represented by a set of its major views, and each major view is represented by a triple chain structure. The triple chain structure that was extracted from the image and the set of triple chain structures representing the major views (view classes) are input to the matching algorithm which tries to identify the view class or classes that most closely match the view in the image. This process illustrates the kind of experiments that modelare simpler than the one shown, and some are much more complex.},
note = {LA-UR-pending},
keywords = {model-based computer vision, visual database},
pubstate = {published},
tppubtype = {inproceedings}
}
Computer vision researchers work with many different forms of data. Model-based vision systems work with geometric models of 3D objects, intensity or range images, and many different kinds of features that are extracted from these images. The recognition/pose estimation process involves a number of different steps and different operations all of which take in and generate various forms of data. Figure 1 illustrates the operations and data types required for a sample recognition process (Shapiro, Neal, and Ponder; 1992). The process starts with a gray-scale image and produces an edge image, a line segment structure, and a triple chain structure (described in Section 2). Each object in the model database is represented by a set of its major views, and each major view is represented by a triple chain structure. The triple chain structure that was extracted from the image and the set of triple chain structures representing the major views (view classes) are input to the matching algorithm which tries to identify the view class or classes that most closely match the view in the image. This process illustrates the kind of experiments that modelare simpler than the one shown, and some are much more complex.
: . .
1.
Shapiro, Linda; Tanimoto, Steven; Brinkley, James; Ahrens, James; Jakobovits, Rex; Lewis, Lara
A visual database system for data and experiment management in model-based computer vision Proceedings Article
In: CAD-Based Vision Workshop, 1994., Proceedings of the 1994 Second, pp. 64–72, IEEE 1994, (LA-UR-pending).
@inproceedings{shapiro1994visual,
title = {A visual database system for data and experiment management in model-based computer vision},
author = {Linda Shapiro and Steven Tanimoto and James Brinkley and James Ahrens and Rex Jakobovits and Lara Lewis},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AVisualDatabaseSystemForDataAndExperimentManagementInModel-BasedComputerVision.pdf},
year = {1994},
date = {1994-01-01},
booktitle = {CAD-Based Vision Workshop, 1994., Proceedings of the 1994 Second},
pages = {64--72},
organization = {IEEE},
abstract = {Computer vision researchers work with many different forms of data. Model-based vision systems work with geometric models of 3D objects, intensity or range images, and many different kinds of features that are extracted from these images. The recognition/pose estimation process involves a number of different steps and different operations all of which take in and generate various forms of data. Figure 1 illustrates the operations and data types required for a sample recognition process (Shapiro, Neal, and Ponder; 1992). The process starts with a gray-scale image and produces an edge image, a line segment structure, and a triple chain structure (described in Section 2). Each object in the model database is represented by a set of its major views, and each major view is represented by a triple chain structure. The triple chain structure that was extracted from the image and the set of triple chain structures representing the major views (view classes) are input to the matching algorithm which tries to identify the view class or classes that most closely match the view in the image. This process illustrates the kind of experiments that modelare simpler than the one shown, and some are much more complex.},
note = {LA-UR-pending},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Computer vision researchers work with many different forms of data. Model-based vision systems work with geometric models of 3D objects, intensity or range images, and many different kinds of features that are extracted from these images. The recognition/pose estimation process involves a number of different steps and different operations all of which take in and generate various forms of data. Figure 1 illustrates the operations and data types required for a sample recognition process (Shapiro, Neal, and Ponder; 1992). The process starts with a gray-scale image and produces an edge image, a line segment structure, and a triple chain structure (described in Section 2). Each object in the model database is represented by a set of its major views, and each major view is represented by a triple chain structure. The triple chain structure that was extracted from the image and the set of triple chain structures representing the major views (view classes) are input to the matching algorithm which tries to identify the view class or classes that most closely match the view in the image. This process illustrates the kind of experiments that modelare simpler than the one shown, and some are much more complex.