2013
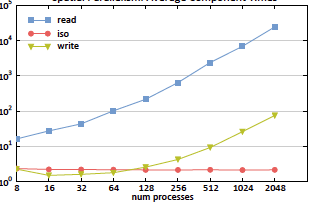
Nouanesengsy, Boonthanome; Patchett, John; Ahrens, James; Bauer, Andrew; Chaudhary, Aashish; Miller, Ross; Geveci, Berk; Shipman, Galen; Williams, Dean N
A model for optimizing file access patterns using spatio-temporal parallelism Proceedings Article
In: Proceedings of the 8th International Workshop on Ultrascale Visualization, pp. 4, ACM 2013, (LA-UR-pending).
Abstract | Links | BibTeX | Tags: Data Analysis, file access, I/O, Modeling, Modeling techniques, optimizing, parallel programming, Parallel Techniques, patio-temporal parallelism, visualization
@inproceedings{nouanesengsy2013model,
title = {A model for optimizing file access patterns using spatio-temporal parallelism},
author = {Boonthanome Nouanesengsy and John Patchett and James Ahrens and Andrew Bauer and Aashish Chaudhary and Ross Miller and Berk Geveci and Galen Shipman and Dean N Williams},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AModelForOptimizingFileAccessPatternsUsingSpatio-TemporalParallelism.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Proceedings of the 8th International Workshop on Ultrascale Visualization},
pages = {4},
organization = {ACM},
abstract = {For many years now, I/O read time has been recognized as the primary bottleneck for parallel visualization and analysis of large-scale data. In this paper, we introduce a model that can estimate the read time for a file stored in a parallel filesystem when given the file access pattern. Read times ultimately depend on how the file is stored and the access pattern used to read the file. The file access pattern will be dictated by the type of parallel decomposition used. We employ spatio-temporal parallelism, which combines both spatial and temporal parallelism, to provide greater flexibility to possible file access patterns. Using our model, we were able to configure the spatio-temporal parallelism to design optimized read access patterns that resulted in a speedup factor of approximately 400 over traditional file access patterns.},
note = {LA-UR-pending},
keywords = {Data Analysis, file access, I/O, Modeling, Modeling techniques, optimizing, parallel programming, Parallel Techniques, patio-temporal parallelism, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
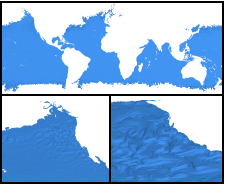
Sewell, Christopher; Lo, Li-ta; Ahrens, James
Portable data-parallel visualization and analysis in distributed memory environments Proceedings Article
In: Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on, pp. 25–33, IEEE 2013, (LA-UR-13-23809).
Abstract | Links | BibTeX | Tags: analysis, Concurrent Programming, data-parallel, distributed memory, parallel programming, PISTON, visualization
@inproceedings{sewell2013portable,
title = {Portable data-parallel visualization and analysis in distributed memory environments},
author = {Christopher Sewell and Li-ta Lo and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/PortableData-ParallelVisualizationAndAnalysisInDistributedMemoryEnvironments.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on},
pages = {25--33},
organization = {IEEE},
abstract = {Data-parallelism is a programming model that maps well to architectures with a high degree of concurrency. Algorithms written using data-parallel primitives can be easily ported to any architecture for which an implementation of these primitives exists, making efficient use of the available parallelism on each. We have previously published results demonstrating our ability to compile the same data-parallel code for several visualization algorithms onto different on-node parallel architectures (GPUs and multi-core CPUs) using our extension of NVIDIAÕs Thrust library. In this paper, we discuss our extension of Thrust to support concurrency in distributed memory environments across multiple nodes. This enables the application developer to write data-parallel algorithms while viewing the data as single, long vectors, essentially without needing to explicitly take into consideration whether the values are actually distributed across nodes. Our distributed wrapper for Thrust handles the communication in the backend using MPI, while still using the standard Thrust library to take advantage of available on-node parallelism. We describe the details of our distributed implementations of several key data-parallel primitives, including scan, scatter/ gather, sort, reduce, and upper/lower bound. We also present two higher-level distributed algorithms developed using these primitives: isosurface and KD-tree construction. Finally, we provide timing results demonstrating the ability of these algorithms to take advantage of available parallelism on nodes and across multiple nodes, and discuss scaling limitations for communication-intensive algorithms such as KD-tree construction.},
note = {LA-UR-13-23809},
keywords = {analysis, Concurrent Programming, data-parallel, distributed memory, parallel programming, PISTON, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
2012
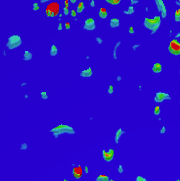
Lo, Li-ta; Sewell, Christopher; Ahrens, James
PISTON: A Portable Cross-Platform Framework for Data-Parallel Visualization Operators. Proceedings Article
In: EGPGV, pp. 11–20, 2012, (LA-UR-12-10227).
Abstract | Links | BibTeX | Tags: Concurrent Programming, parallel programming, PISTON
@inproceedings{lo2012piston,
title = {PISTON: A Portable Cross-Platform Framework for Data-Parallel Visualization Operators.},
author = {Li-ta Lo and Christopher Sewell and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/PISTONAPortableCrossPlatformFrameworkForData-ParallelVisualizationOperators.pdf},
year = {2012},
date = {2012-01-01},
booktitle = {EGPGV},
pages = {11--20},
abstract = {Due to the wide variety of current and next-generation supercomputing architectures, the development of highperformance parallel visualization and analysis operators frequently requires re-writing the underlying algorithms for many different platforms. In order to facilitate portability, we have devised a framework for creating such operators that employs the data-parallel programming model. By writing the operators using only data-parallel primitives (such as scans, transforms, stream compactions, etc.), the same code may be compiled to multiple targets using architecture-specific backend implementations of these primitives. Specifically, we make use of and extend NVIDIAÕs Thrust library, which provides CUDA and OpenMP backends. Using this framework, we have implemented isosurface, cut surface, and threshold operators, and have achieved good parallel performance on two different architectures (multi-core CPUs and NVIDIA GPUs) using the exact same operator code. We have applied these operators to several large, real scientific data sets, and have open-source released a beta version of our code base.},
note = {LA-UR-12-10227},
keywords = {Concurrent Programming, parallel programming, PISTON},
pubstate = {published},
tppubtype = {inproceedings}
}
Nouanesengsy, Boonthanome; Patchett, John; Ahrens, James; Bauer, Andrew; Chaudhary, Aashish; Miller, Ross; Geveci, Berk; Shipman, Galen; Williams, Dean N
A model for optimizing file access patterns using spatio-temporal parallelism Proceedings Article
In: Proceedings of the 8th International Workshop on Ultrascale Visualization, pp. 4, ACM 2013, (LA-UR-pending).
@inproceedings{nouanesengsy2013model,
title = {A model for optimizing file access patterns using spatio-temporal parallelism},
author = {Boonthanome Nouanesengsy and John Patchett and James Ahrens and Andrew Bauer and Aashish Chaudhary and Ross Miller and Berk Geveci and Galen Shipman and Dean N Williams},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AModelForOptimizingFileAccessPatternsUsingSpatio-TemporalParallelism.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Proceedings of the 8th International Workshop on Ultrascale Visualization},
pages = {4},
organization = {ACM},
abstract = {For many years now, I/O read time has been recognized as the primary bottleneck for parallel visualization and analysis of large-scale data. In this paper, we introduce a model that can estimate the read time for a file stored in a parallel filesystem when given the file access pattern. Read times ultimately depend on how the file is stored and the access pattern used to read the file. The file access pattern will be dictated by the type of parallel decomposition used. We employ spatio-temporal parallelism, which combines both spatial and temporal parallelism, to provide greater flexibility to possible file access patterns. Using our model, we were able to configure the spatio-temporal parallelism to design optimized read access patterns that resulted in a speedup factor of approximately 400 over traditional file access patterns.},
note = {LA-UR-pending},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Sewell, Christopher; Lo, Li-ta; Ahrens, James
Portable data-parallel visualization and analysis in distributed memory environments Proceedings Article
In: Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on, pp. 25–33, IEEE 2013, (LA-UR-13-23809).
@inproceedings{sewell2013portable,
title = {Portable data-parallel visualization and analysis in distributed memory environments},
author = {Christopher Sewell and Li-ta Lo and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/PortableData-ParallelVisualizationAndAnalysisInDistributedMemoryEnvironments.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on},
pages = {25--33},
organization = {IEEE},
abstract = {Data-parallelism is a programming model that maps well to architectures with a high degree of concurrency. Algorithms written using data-parallel primitives can be easily ported to any architecture for which an implementation of these primitives exists, making efficient use of the available parallelism on each. We have previously published results demonstrating our ability to compile the same data-parallel code for several visualization algorithms onto different on-node parallel architectures (GPUs and multi-core CPUs) using our extension of NVIDIAÕs Thrust library. In this paper, we discuss our extension of Thrust to support concurrency in distributed memory environments across multiple nodes. This enables the application developer to write data-parallel algorithms while viewing the data as single, long vectors, essentially without needing to explicitly take into consideration whether the values are actually distributed across nodes. Our distributed wrapper for Thrust handles the communication in the backend using MPI, while still using the standard Thrust library to take advantage of available on-node parallelism. We describe the details of our distributed implementations of several key data-parallel primitives, including scan, scatter/ gather, sort, reduce, and upper/lower bound. We also present two higher-level distributed algorithms developed using these primitives: isosurface and KD-tree construction. Finally, we provide timing results demonstrating the ability of these algorithms to take advantage of available parallelism on nodes and across multiple nodes, and discuss scaling limitations for communication-intensive algorithms such as KD-tree construction.},
note = {LA-UR-13-23809},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Lo, Li-ta; Sewell, Christopher; Ahrens, James
PISTON: A Portable Cross-Platform Framework for Data-Parallel Visualization Operators. Proceedings Article
In: EGPGV, pp. 11–20, 2012, (LA-UR-12-10227).
@inproceedings{lo2012piston,
title = {PISTON: A Portable Cross-Platform Framework for Data-Parallel Visualization Operators.},
author = {Li-ta Lo and Christopher Sewell and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/PISTONAPortableCrossPlatformFrameworkForData-ParallelVisualizationOperators.pdf},
year = {2012},
date = {2012-01-01},
booktitle = {EGPGV},
pages = {11--20},
abstract = {Due to the wide variety of current and next-generation supercomputing architectures, the development of highperformance parallel visualization and analysis operators frequently requires re-writing the underlying algorithms for many different platforms. In order to facilitate portability, we have devised a framework for creating such operators that employs the data-parallel programming model. By writing the operators using only data-parallel primitives (such as scans, transforms, stream compactions, etc.), the same code may be compiled to multiple targets using architecture-specific backend implementations of these primitives. Specifically, we make use of and extend NVIDIAÕs Thrust library, which provides CUDA and OpenMP backends. Using this framework, we have implemented isosurface, cut surface, and threshold operators, and have achieved good parallel performance on two different architectures (multi-core CPUs and NVIDIA GPUs) using the exact same operator code. We have applied these operators to several large, real scientific data sets, and have open-source released a beta version of our code base.},
note = {LA-UR-12-10227},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}