2015
Sewell, Christopher; Heitmann, Katrin; Finkel, Hal; Zagaris, George; Parete-Koon, Suzanne; Fasel, Patricia; Pope, Adrian; Frontiere, Nicholas; Lo, Li-Ta; Messer, Bronson; Habib, Salman; Ahrens, James
Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Press, Austin, Texas, 2015, (LA-UR-15-22830).
Abstract | Links | BibTeX | Tags: analysis, co-scheduling, compute-intensive, in-situ, large-scale, workflow
@inproceedings{Sewell:2015b,
title = {Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach},
author = {Christopher Sewell and Katrin Heitmann and Hal Finkel and George Zagaris and Suzanne Parete-Koon and Patricia Fasel and Adrian Pope and Nicholas Frontiere and Li-Ta Lo and Bronson Messer and Salman Habib and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/Large-ScaleCompute-IntensiveAnalysisViaACombinedIn-situAndCo-schedulingWorkflowApproach.pdf},
year = {2015},
date = {2015-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
publisher = {IEEE Press},
address = {Austin, Texas},
series = {SC '15},
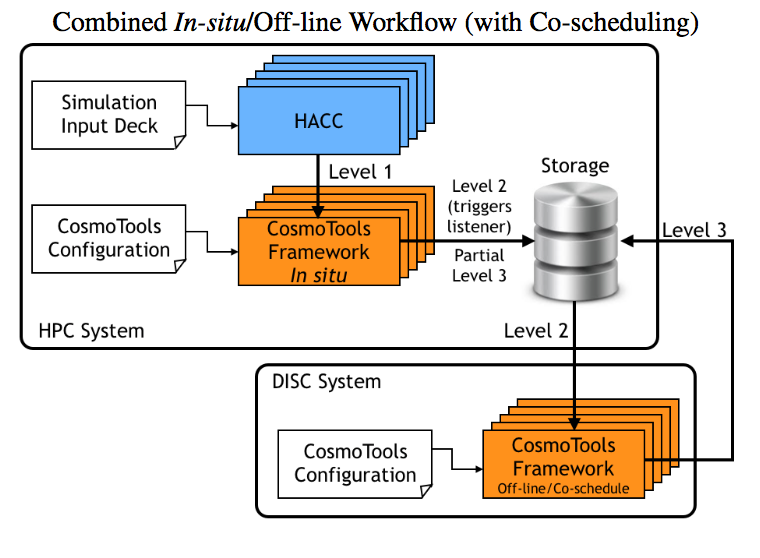
abstract = {Large-scale simulations can produce hundreds of terabytes to peta- bytes of data, complicating and limiting the efficiency of work- flows. Traditionally, outputs are stored on the file system and an- alyzed in post-processing. With the rapidly increasing size and complexity of simulations, this approach faces an uncertain future. Trending techniques consist of performing the analysis in-situ, uti- lizing the same resources as the simulation, and/or off-loading sub- sets of the data to a compute-intensive analysis system. We intro- duce an analysis framework developed for HACC, a cosmological N-body code, that uses both in-situ and co-scheduling approaches for handling petabyte-scale outputs. We compare different anal- ysis set-ups ranging from purely off-line, to purely in-situ to in- situ/co-scheduling. The analysis routines are implemented using the PISTON/VTK-m framework, allowing a single implementation of an algorithm that simultaneously targets a variety of GPU, multi- core, and many-core architectures.},
note = {LA-UR-15-22830},
keywords = {analysis, co-scheduling, compute-intensive, in-situ, large-scale, workflow},
pubstate = {published},
tppubtype = {inproceedings}
}
2014

Ahrens, James; Jourdain, Sebastien; O'Leary, Patrick; Patchett, John; Rogers, David; Petersen, Mark
An Image-based Approach to Extreme Scale in Situ Visualization and Analysis Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 424–434, IEEE Press, New Orleans, Louisana, 2014, ISBN: 978-1-4799-5500-8, (LA-UR-14-26864).
Abstract | Links | BibTeX | Tags: analysis, cinema, cinemascience, image-based, in-situ, visualization
@inproceedings{Ahrens:2014:IAE:2683593.2683640,
title = {An Image-based Approach to Extreme Scale in Situ Visualization and Analysis},
author = {James Ahrens and Sebastien Jourdain and Patrick O'Leary and John Patchett and David Rogers and Mark Petersen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AnImage-basedApproachToExtremeScaleInSituvisualizationAndAnalysis.pdf
http://dx.doi.org/10.1109/SC.2014.40},
doi = {10.1109/SC.2014.40},
isbn = {978-1-4799-5500-8},
year = {2014},
date = {2014-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
pages = {424--434},
publisher = {IEEE Press},
address = {New Orleans, Louisana},
series = {SC '14},
abstract = {Extreme scale scientific simulations are leading a charge to exascale computation, and data analytics runs the risk of being a bottleneck to scientific discovery. Due to power and I/O constraints, we expect in situ visualization and analysis will be a critical component of these workflows. Options for extreme scale data analysis are often presented as a stark contrast: write large files to disk for interactive, exploratory analysis, or perform in situ analysis to save detailed data about phenomena that a scientists knows about in advance. We present a novel framework for a third option - a highly interactive, image-based approach that promotes exploration of simulation results, and is easily accessed through extensions to widely used open source tools. This in situ approach supports interactive exploration of a wide range of results, while still significantly reducing data movement and storage.},
note = {LA-UR-14-26864},
keywords = {analysis, cinema, cinemascience, image-based, in-situ, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
2013
Sewell, Christopher; Lo, Li-ta; Ahrens, James
Portable data-parallel visualization and analysis in distributed memory environments Proceedings Article
In: Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on, pp. 25–33, IEEE 2013, (LA-UR-13-23809).
Abstract | Links | BibTeX | Tags: analysis, Concurrent Programming, data-parallel, distributed memory, parallel programming, PISTON, visualization
@inproceedings{sewell2013portable,
title = {Portable data-parallel visualization and analysis in distributed memory environments},
author = {Christopher Sewell and Li-ta Lo and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/PortableData-ParallelVisualizationAndAnalysisInDistributedMemoryEnvironments.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on},
pages = {25--33},
organization = {IEEE},
abstract = {Data-parallelism is a programming model that maps well to architectures with a high degree of concurrency. Algorithms written using data-parallel primitives can be easily ported to any architecture for which an implementation of these primitives exists, making efficient use of the available parallelism on each. We have previously published results demonstrating our ability to compile the same data-parallel code for several visualization algorithms onto different on-node parallel architectures (GPUs and multi-core CPUs) using our extension of NVIDIAÕs Thrust library. In this paper, we discuss our extension of Thrust to support concurrency in distributed memory environments across multiple nodes. This enables the application developer to write data-parallel algorithms while viewing the data as single, long vectors, essentially without needing to explicitly take into consideration whether the values are actually distributed across nodes. Our distributed wrapper for Thrust handles the communication in the backend using MPI, while still using the standard Thrust library to take advantage of available on-node parallelism. We describe the details of our distributed implementations of several key data-parallel primitives, including scan, scatter/ gather, sort, reduce, and upper/lower bound. We also present two higher-level distributed algorithms developed using these primitives: isosurface and KD-tree construction. Finally, we provide timing results demonstrating the ability of these algorithms to take advantage of available parallelism on nodes and across multiple nodes, and discuss scaling limitations for communication-intensive algorithms such as KD-tree construction.},
note = {LA-UR-13-23809},
keywords = {analysis, Concurrent Programming, data-parallel, distributed memory, parallel programming, PISTON, visualization},
pubstate = {published},
tppubtype = {inproceedings}
}
Sewell, Christopher; Heitmann, Katrin; Finkel, Hal; Zagaris, George; Parete-Koon, Suzanne; Fasel, Patricia; Pope, Adrian; Frontiere, Nicholas; Lo, Li-Ta; Messer, Bronson; Habib, Salman; Ahrens, James
Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE Press, Austin, Texas, 2015, (LA-UR-15-22830).
@inproceedings{Sewell:2015b,
title = {Large-Scale Compute-Intensive Analysis via a Combined In-situ and Co-scheduling Workflow Approach},
author = {Christopher Sewell and Katrin Heitmann and Hal Finkel and George Zagaris and Suzanne Parete-Koon and Patricia Fasel and Adrian Pope and Nicholas Frontiere and Li-Ta Lo and Bronson Messer and Salman Habib and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/Large-ScaleCompute-IntensiveAnalysisViaACombinedIn-situAndCo-schedulingWorkflowApproach.pdf},
year = {2015},
date = {2015-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
publisher = {IEEE Press},
address = {Austin, Texas},
series = {SC '15},
abstract = {Large-scale simulations can produce hundreds of terabytes to peta- bytes of data, complicating and limiting the efficiency of work- flows. Traditionally, outputs are stored on the file system and an- alyzed in post-processing. With the rapidly increasing size and complexity of simulations, this approach faces an uncertain future. Trending techniques consist of performing the analysis in-situ, uti- lizing the same resources as the simulation, and/or off-loading sub- sets of the data to a compute-intensive analysis system. We intro- duce an analysis framework developed for HACC, a cosmological N-body code, that uses both in-situ and co-scheduling approaches for handling petabyte-scale outputs. We compare different anal- ysis set-ups ranging from purely off-line, to purely in-situ to in- situ/co-scheduling. The analysis routines are implemented using the PISTON/VTK-m framework, allowing a single implementation of an algorithm that simultaneously targets a variety of GPU, multi- core, and many-core architectures.},
note = {LA-UR-15-22830},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Ahrens, James; Jourdain, Sebastien; O'Leary, Patrick; Patchett, John; Rogers, David; Petersen, Mark
An Image-based Approach to Extreme Scale in Situ Visualization and Analysis Proceedings Article
In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, pp. 424–434, IEEE Press, New Orleans, Louisana, 2014, ISBN: 978-1-4799-5500-8, (LA-UR-14-26864).
@inproceedings{Ahrens:2014:IAE:2683593.2683640,
title = {An Image-based Approach to Extreme Scale in Situ Visualization and Analysis},
author = {James Ahrens and Sebastien Jourdain and Patrick O'Leary and John Patchett and David Rogers and Mark Petersen},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/AnImage-basedApproachToExtremeScaleInSituvisualizationAndAnalysis.pdf
http://dx.doi.org/10.1109/SC.2014.40},
doi = {10.1109/SC.2014.40},
isbn = {978-1-4799-5500-8},
year = {2014},
date = {2014-01-01},
booktitle = {Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis},
pages = {424--434},
publisher = {IEEE Press},
address = {New Orleans, Louisana},
series = {SC '14},
abstract = {Extreme scale scientific simulations are leading a charge to exascale computation, and data analytics runs the risk of being a bottleneck to scientific discovery. Due to power and I/O constraints, we expect in situ visualization and analysis will be a critical component of these workflows. Options for extreme scale data analysis are often presented as a stark contrast: write large files to disk for interactive, exploratory analysis, or perform in situ analysis to save detailed data about phenomena that a scientists knows about in advance. We present a novel framework for a third option - a highly interactive, image-based approach that promotes exploration of simulation results, and is easily accessed through extensions to widely used open source tools. This in situ approach supports interactive exploration of a wide range of results, while still significantly reducing data movement and storage.},
note = {LA-UR-14-26864},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Sewell, Christopher; Lo, Li-ta; Ahrens, James
Portable data-parallel visualization and analysis in distributed memory environments Proceedings Article
In: Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on, pp. 25–33, IEEE 2013, (LA-UR-13-23809).
@inproceedings{sewell2013portable,
title = {Portable data-parallel visualization and analysis in distributed memory environments},
author = {Christopher Sewell and Li-ta Lo and James Ahrens},
url = {http://datascience.dsscale.org/wp-content/uploads/2016/06/PortableData-ParallelVisualizationAndAnalysisInDistributedMemoryEnvironments.pdf},
year = {2013},
date = {2013-01-01},
booktitle = {Large-Scale Data Analysis and Visualization (LDAV), 2013 IEEE Symposium on},
pages = {25--33},
organization = {IEEE},
abstract = {Data-parallelism is a programming model that maps well to architectures with a high degree of concurrency. Algorithms written using data-parallel primitives can be easily ported to any architecture for which an implementation of these primitives exists, making efficient use of the available parallelism on each. We have previously published results demonstrating our ability to compile the same data-parallel code for several visualization algorithms onto different on-node parallel architectures (GPUs and multi-core CPUs) using our extension of NVIDIAÕs Thrust library. In this paper, we discuss our extension of Thrust to support concurrency in distributed memory environments across multiple nodes. This enables the application developer to write data-parallel algorithms while viewing the data as single, long vectors, essentially without needing to explicitly take into consideration whether the values are actually distributed across nodes. Our distributed wrapper for Thrust handles the communication in the backend using MPI, while still using the standard Thrust library to take advantage of available on-node parallelism. We describe the details of our distributed implementations of several key data-parallel primitives, including scan, scatter/ gather, sort, reduce, and upper/lower bound. We also present two higher-level distributed algorithms developed using these primitives: isosurface and KD-tree construction. Finally, we provide timing results demonstrating the ability of these algorithms to take advantage of available parallelism on nodes and across multiple nodes, and discuss scaling limitations for communication-intensive algorithms such as KD-tree construction.},
note = {LA-UR-13-23809},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}